Automatiser le développement d'applications
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Téléchargement de la version de CodeWorker hébergée sur Developpez.com | |
| Binaire pour les plateformes Windows | CodeWorker/CodeWorker_WIN3_8.zip |
| Sources pour toutes les plateformes | CodeWorker/CodeWorker_SRC3_8.zip |
| Documentation en ligne | ScriptLanguage.html |
| Documentation PDF | CodeWorker/CodeWorker.pdf |
- les scripts d'enchainement ou de liaison (ni parsing BNF, ni génération de code); extension en ".cws",
- les scripts de parsing BNF; extension en ".cwp",
- les scripts de génération de code; extension en ".cwt", le t final pour template-based script en anglais,
- exécution d'un script d'enchainement monScript.cws :
codeworker monScript.cws
alternative vieillote :
codeworker -script monScript.cws - exécution d'un script de parsing BNF monScript.cwp sur un fichier monTexteAParser.txt :
codeworker -parsebnf monScript.cwp monTexteAParser.txt - exécution d'un script de génération de code monScript.cwt sur un fichier monTexteAGenerer.txt.
- Génération classique :
codeworker -generate monScript.cwt monTexteAGenerer.txt - Expansion de code (génération à certains points du fichier) :
codeworker -expand monScript.cwt monTexteAGenerer.txt - Auto expansion de code. Ici, le(s) script(s) de génération de code est(sont) incrusté(s) dans le fichier texte :
codeworker -autoexpand monTexteAGenerer.txt
- Génération classique :
- exécution d'un script de transformation de code monScript.cwp, avec lecture d'un fichier
monTexteAParser.txt et écriture dans un fichier monTexteAGenerer.txt. Si les deux fichiers sont
les mêmes, il s'agit d'une transformation. S'ils sont différents, on parle de traduction.
codeworker -translate monScript.cwp monTexteAParser.txt monTexteAGenerer.txt
codeworker -help CodeWorker manipule un type unique de structure de données, qui offre la possibilité de stocker une valeur, une référence sur une autre donnée, une liste d'éléments (ou, plus généralement, une table d'association) et une structure d'arbre.
Une donnée peut représenter tout cela à la fois. Il existe une variable globale appelée project, toujours présente et accessible de tous les scripts.
Cette variable est souvent utilisée pour y stocker les informations utiles lors du parsing et les transmettre à la génération de code, mais ce n'est pas une obligation car on peut à tout moment déclarer une variable locale.
La particularité d'une variable locale est d'être placée sur la pile de l'application, ce qui contraint sa durée de vie au temps passé dans le bloc d'instructions où elle a été déclarée. Une fois sortie du bloc d'instructions, la variable locale est détruite.
| Le type unique de structure de données |
|
Une valeur peut se révéler un nombre entier ou flottant, un booléen ou une chaîne de caractères. A propos des valeurs
booléennes, il faut savoir que le faux se représente par une chaîne de caractères vide (mot-clé false),
et qu'un nombre ou toute chaîne de caractères non vide signifie vrai ; dans ce dernier cas, on peut cependant
utiliser la constante true (qui vaut la chaîne de caractères "true") pour forcer à vrai.
Exemples:
Une table d'association se présente comme un tableau, qui a la particularité d'être non pas forcément indicé par un entier, mais par n'importe quel type de valeur. Dans CodeWorker, les tables d'association sont indicées par des nombres (entiers ou flottants) ou par des chaînes de caractères, que l'on appelle la clé ou l'entrée dans la table. Exemple : local dictionnaire;
On peut développer un arbre à partir de n'importe quelle variable. La branche qui mène à un noeud fils est nommée par un
identifiant (séquence de caractères alphanumériques, dont le premier n'est pas un chiffre), que l'on appelle aussi
l'attribut.
Exemple :
insert dictionnaire["sardine"] = "Petit poisson marinant dans l'huile"; insert dictionnaire[3.141592] = "Premiers chiffres de Pi"; local jouet;
On remarque ici l'analogie entre la structure d'arbre et celles plus classique de structure C ou de classe C++/Java sans
héritage. On appelle d'ailleurs categorie un attribut de jouet.
insert jouet.categorie = "voiture"; insert jouet.alimentation = "piles"; insert jouet.alimentation.quantite = 4; insert jouet.alimentation.taille = "LR6"; |
|
Si vous omettez le mot-clé insert lors de l'assignation à un attribut ou à un élément non encore existant, un
avertissement est produit par l'interpréteur, ceci afin de pallier l'absence de typage fort dans le langage. En effet,
pour une variable sensée exister, vous n'utiliserez pas le mot-clé insert pour opérer l'assignation. Et si
vous avez introduit une faute de frappe quelque part dans son nom, celle-ci ne sera pas trouvée par l'interpréteur qui
vous avertira.
|
local dessert = "tartelette";
insert dessert.pate = "sablée";
insert dessert.garniture["fraise"] = 8;
insert dessert.garniture["abricot"];
// copie de la valeur seulement : "tartelette"
local copieDessert = dessert;
// copie de tout le graphe 'dessert', tables d'association comprises
setall copieDessert = dessert;
Lorsqu'une copie complète est requise avec setall, la variable assignée est préalablement purgée :
insert dessert.pate = "sablée";
insert dessert.garniture["fraise"] = 8;
insert dessert.garniture["abricot"];
// copie de la valeur seulement : "tartelette"
local copieDessert = dessert;
// copie de tout le graphe 'dessert', tables d'association comprises
setall copieDessert = dessert;
plus de valeur, plus de table d'association, plus de graphe. Dans certains cas, on peut vouloir simplement fusionner cette variable avec une autre. Dans cette opération de fusion, les attributs ou éléments de tables d'association qui n'existent pas dans la variable à fusionner, sont simplement copiés. Ceux qui n'ont pas la même valeur sont modifiés. L'opération de fusion d'une variable dans une autre s'accomplit en introduisant le mot-clé merge en tête de l'instruction d'assignation. Exemple :
local dessert = "tartelette";
insert dessert.pate = "sablée";
insert dessert.garniture["fraise"] = 8;
insert dessert.garniture["abricot"];
local nouvelleRecette = "tarte";
insert nouvelleRecette.thermostat = "7/8";
insert nouvelleRecette.garniture["banane"] = 1;
merge dessert = nouvelleRecette;
// après le 'merge', la variable 'dessert' vaut:
// dessert = "tarte";
// dessert.pate = "sablée";
// dessert.thermostat = "7/8";
// dessert.garniture["fraise"] = 8;
// dessert.garniture["abricot"] = "";
// dessert.garniture["banane"] = 1;
Il peut arriver qu'une variable doivent faire référence à une donnée, de telle sorte que lorsqu'on manipule le référant,
ce soit propagé sur le référé. C'est l'instruction ref qui se charge d'établir la référence.
Exemple :
insert dessert.pate = "sablée";
insert dessert.garniture["fraise"] = 8;
insert dessert.garniture["abricot"];
local nouvelleRecette = "tarte";
insert nouvelleRecette.thermostat = "7/8";
insert nouvelleRecette.garniture["banane"] = 1;
merge dessert = nouvelleRecette;
// après le 'merge', la variable 'dessert' vaut:
// dessert = "tarte";
// dessert.pate = "sablée";
// dessert.thermostat = "7/8";
// dessert.garniture["fraise"] = 8;
// dessert.garniture["abricot"] = "";
// dessert.garniture["banane"] = 1;
local especeAnimale;
insert especeAnimale["Mireille"] = "abeille";
insert especeAnimale["Camille"] = "chenille";
local insecte;
ref insecte = especeAnimale["Mireille"];
// dorénavant, la variable 'insecte' pointe sur 'especeAnimale["Mireille"]';
// nous insérons un nouvel attribut pour obtenir :
// 'especeAnimale["Mireille"].adresse = "sous le rosier"'
// au travers du référant 'insecte'
insert insecte.adresse = "sous le rosier";
// l'instruction 'localref' est un raccourci pour, en une seule fois,
// déclarer une variable locale et établir la référence
localref rampant = especeAnimale["Camille"];
La syntaxe d'un appel de fonction est similaire à celle des langages de la famille du C, à savoir un identifiant
suivi d'arguments séparés par des virgules, et placées entre parenthèses. L'identifiant est le nom de la fonction. Une
procédure est une fonction qui ne renvoie pas de paramètres.
Exemples :
insert especeAnimale["Mireille"] = "abeille";
insert especeAnimale["Camille"] = "chenille";
local insecte;
ref insecte = especeAnimale["Mireille"];
// dorénavant, la variable 'insecte' pointe sur 'especeAnimale["Mireille"]';
// nous insérons un nouvel attribut pour obtenir :
// 'especeAnimale["Mireille"].adresse = "sous le rosier"'
// au travers du référant 'insecte'
insert insecte.adresse = "sous le rosier";
// l'instruction 'localref' est un raccourci pour, en une seule fois,
// déclarer une variable locale et établir la référence
localref rampant = especeAnimale["Camille"];
// cliquez sur le nom des fonctions pour connaître leur signification
cutString(maChaine, ';', listeResultat);
prefix = leftString(listeResultat#back, 4);
// affiche la date du jour au format 'dd/mm/yyyy'
traceLine(formatDate(getNow(), "%d/%m/%Y"));
Le seul type de retour autorisé pour une fonction est un type de base : chaîne de caractères, entier, booléen, nombre
flottant. En aucun cas une fonction ne retournera une référence sur une variable, un graphe ou une table d'association. Si
cela s'avérait malgré tout nécessaire, le paramètre de retour devra figurer comme argument de la fonction, passé par référence
(mode by node).
Si le premier paramètre d'une fonction ou d'une procédure est une variable, il existe une écriture pseudo-appel de méthode
qui apporte parfois plus de clarté à la lecture du script :
cutString(maChaine, ';', listeResultat);
prefix = leftString(listeResultat#back, 4);
// affiche la date du jour au format 'dd/mm/yyyy'
traceLine(formatDate(getNow(), "%d/%m/%Y"));
maChaine.cutString(';', listeResultat);
prefix = listeResultat#back.leftString(4);
// ici, les premiers paramètres sont des appels de fonction :
// l'écriture en pseudo-méthode n'est pas permise
traceLine(formatDate(getNow(), "%d/%m/%Y"));
CodeWorker propose un certain nombre de fonctions et procédures prédéfinies, dans des domaines aussi variés que la
manipulation des chaînes de caractères, des nombres ou des dates, la gestion de fichiers et de répertoires, la manipulation
des noeuds d'un graphe, celle des éléments d'un tableau, quelques commandes système...
prefix = listeResultat#back.leftString(4);
// ici, les premiers paramètres sont des appels de fonction :
// l'écriture en pseudo-méthode n'est pas permise
traceLine(formatDate(getNow(), "%d/%m/%Y"));
Elles sont toutes recensées par catégorie sur le site de CodeWorker à l'adresse http://www.codeworker.org/Documentation.html. Deux procédures nous serons particulièrement utiles par la suite : traceLine() et traceObject(). La première écrit une ligne de texte dans la console, tandis que la seconde décrit la structure de premier niveau d'une variable : sa valeur, ses attributs directs (avec leur valeur et les clés de leur table d'association éventuelle) et sa table d'association.
Ces deux procédures sont très utiles à des fins de trace ou d'exploration du contenu d'une variable. Pour faire bonne mesure, introduisons la procédure saveProject(). Elle se charge de sauver au format XML la structure complète de la variable project, dont nous avons déjà parlé plus haut. Si vous avez pris soin d'alimenter cette variable avec toute l'information utile, le fichier XML sera son reflet exact, et facilitera par là-même la mise au point de vos scripts. Le programmeur peut implanter ses propres fonctions. L'implantation d'une fonction est annoncée par le mot-cle function.
Les paramètres sont passés soit par valeur (mode par défaut), soit par référence. Le corps de la fonction est placé entre accolades. Une fonction ne peut retourner qu'une valeur, à l'exclusion de tout autre type (graphe, table d'association, référence sur une variable). Pour ce faire, on se sert du mot-clé return, éventuellement suivi d'une expression. Une fonction qui ne retourne pas de valeur rend toujours une chaîne vide. Exemple :
// passage par référence: 'node'
// passage par valeur : 'value'
function salleMachine(bateau : node, commande : value) {
if commande == "avant toute" {
bateau.vitesse = "15 noeuds";
return true;
}
return false;
}
local yacht;
if !salleMachine(yacht, "avant toute") error("Le mécanicien a rejeté l'ordre");
traceLine("vitesse = " + yacht.vitesse);
Par défaut, les expressions s'appliquent aux chaînes de caractères, et non pas aux nombres. Les constantes numériques sont
traduites en écriture base 10 sous la forme d'une séquence de caractères, donc toutes les valeurs sont manipulées comme
des chaînes de caractères. L'opérateur + sert par exemple à concaténer les chaînes et non pas à
sommer des nombres.
Les opérateurs de comparaison travaillent eux-aussi sur les chaînes. Ainsi, (2 < 10) échoue car, en
réalité, c'est la comparaison ("2" < "10") des chaînes de caractère
correspondantes qui est réalisée.
Dans un contexte d'analyse syntaxique et de génération de code, il est rarissime d'avoir besoin de calculer sur des
nombres, puisque soit l'un, soit l'autre, ont pour tâche de manipuler du texte. C'est pourquoi ce n'est absolument pas
vécu comme une contrainte d'exécuter les expressions sur les chaînes. Cependant, pour les cas où il reste indispensable de
résoudre des expressions sur les nombres, il existe un moyen pour basculer en mode "résolution d'expressions
arithmétiques" : il suffit de placer l'expression entre symboles '$'. Ainsi, la comparaison
$2 < 10$ devient vraie, et $2 + 10$ donne 12 et non pas "210".
Comme la plupart des langages, CodeWorker admet un certain nombre de structures de contrôle. Nous avons eu l'occasion
de croiser l'instruction if au sein d'un précédent exemple. Il existe aussi le
while et le do... while. Tous ressemblent
beaucoup à leurs cousins C, C++ et Java, à la différence près qu'il n'est pas imposé de mettre les conditions entre
parenthèses.
Il existe encore d'autres structures de contrôle, mais seuls le foreach et le
switch seront abordés dans la suite de cette section.
L'instruction foreach sert à itérer les éléments d'une table d'association. Un index pointe
sur l'élément courant de la table d'association. Il y a trois fonctions qui ne peuvent s'appliquer que sur les indices de
boucle.
// passage par valeur : 'value'
function salleMachine(bateau : node, commande : value) {
if commande == "avant toute" {
bateau.vitesse = "15 noeuds";
return true;
}
return false;
}
local yacht;
if !salleMachine(yacht, "avant toute") error("Le mécanicien a rejeté l'ordre");
traceLine("vitesse = " + yacht.vitesse);
La première, key(), permet d'obtenir la clé associée à l'élément courant de la table d'association.
La seconde, first(), retourne vrai si l'index pointe sur le premier élément parcouru de la table.
La troisième, last(), retourne vrai si l'index pointe sur le dernier élément parcouru de la table. Exemple :
local especeAnimale;
insert especeAnimale["Mireille"] = "abeille";
insert especeAnimale["Camille"] = "chenille";
foreach i in especeAnimale {
if first(i) {
traceLine("premier élément = '" + i.key() + "'");
} else if last(i) {
traceLine("dernier élément = '" + i.key() + "'");
}
traceLine("clé = '" + key(i) + "' valeur = '" + i + "'");
}
donne à la console :
insert especeAnimale["Mireille"] = "abeille";
insert especeAnimale["Camille"] = "chenille";
foreach i in especeAnimale {
if first(i) {
traceLine("premier élément = '" + i.key() + "'");
} else if last(i) {
traceLine("dernier élément = '" + i.key() + "'");
}
traceLine("clé = '" + key(i) + "' valeur = '" + i + "'");
}
premier élément = 'Mireille'
clé = 'Mireille' valeur = 'abeille'
dernier élément = 'Camille'
clé = 'Camille' valeur = 'chenille'
L'instruction switch a ceci de particulier qu'elle aiguille sur des chaînes de caractères,
contrairement à sa congénère C, C++ ou Java, qui aiguille sur des numéraires. Pour ceux qui ne sont pas familiers avec
comportement de cette commande, rappelons qu'elle permet de sauter directement à un certain bloc d'instructions (parmi
plusieurs proposés), conditionnellement à la valeur prise par une expression donnée. Pour le reste, vous en apprendrez plus
par l'exemple.
Exemple :
clé = 'Mireille' valeur = 'abeille'
dernier élément = 'Camille'
clé = 'Camille' valeur = 'chenille'
switch(maValeur) {
case "salade":
case "radis":
traceLine("légume");
// sortir du 'switch' à présent
break;
case "tomate":
traceText("considéré comme légume, mais c'est un ");
// on continue en séquence
case "orange":
case "banane":
traceLine("fruit");
break;
// ce cas prend toutes les valeurs qui commencent par 'pomme'
start "pomme":
traceLine("pomme ou pomme de terre");
break;
default:
// aucun des cas précédents n'a reconnu 'maValeur',
// traitement par défaut
traceLine("'" + maValeur + "' non reconnu!");
}
Si l'on omet le default et qu'une valeur n'est reconnue par aucun des cas du switch, une erreur sera
remontée à l'exécution.
case "salade":
case "radis":
traceLine("légume");
// sortir du 'switch' à présent
break;
case "tomate":
traceText("considéré comme légume, mais c'est un ");
// on continue en séquence
case "orange":
case "banane":
traceLine("fruit");
break;
// ce cas prend toutes les valeurs qui commencent par 'pomme'
start "pomme":
traceLine("pomme ou pomme de terre");
break;
default:
// aucun des cas précédents n'a reconnu 'maValeur',
// traitement par défaut
traceLine("'" + maValeur + "' non reconnu!");
}
On aura remarqué une originalité : start est un cas qui prend toutes les valeurs commençant par une portion de texte bien définie. Pour l'accomplissement des tâches d'analyse syntaxique, CodeWorker s'inspire de la notation utilisée pour décrire les grammaires formelles, appelée Backus-Naur Form, ou BNF pour les initiés. Dans l'outil, cette notation a été bien étendue pour rendre l'écriture des scripts de parsing la plus efficace possible. Partons d'un exemple de script pour découvrir quelques concepts :
entier ::= ['-']? ['0'..'9']+;
flottant ::= entier '.' entier ['e' entier]?;
nombre ::= flottant | entier;
Nous avons décrit là trois règles de production.
flottant ::= entier '.' entier ['e' entier]?;
nombre ::= flottant | entier;
La première définit ce qu'est un entier : une séquence de chiffres décimaux, éventuellement précédée d'un signe négatif.
La deuxième précise comment écrire un nombre flottant : parties entière et fractionnaire séparées par un point (notation anglo-saxonne), et éventuellement un exposant. Ici, pour ne pas alourdir la grammaire mais surtout afin d'introduire plus bas un opérateur spécial, nous restons laxistes et nous autorisons temporairement la partie fractionnaire à être négative.
La troisième prétend qu'un nombre est soit un flottant, soit un entier. A présent, un peu de terminologie : les règles de production sont composées d'une séquence de symboles BNF (entier '.' entier ['e' entier]? par exemple), ou d'alternatives parmi des séquences de symboles BNF (flottant | entier offre deux alternatives : soit la séquence BNF entier, soit la séquence BNF flottant). Un symbole BNF est dit terminal s'il se limite à une constante ('-' et 'e') ou à un intervalle de constantes ('0'..'9').
Un symbole BNF est dit non-terminal s'il conduit à appeler une autre règle de production (dans la séquence entier '.' entier ['e' entier]?, entier est un symbole non-terminal).
Pour les puristes, par abus de langage mais pour simplifier le discours, on considère aussi la répétition d'une séquence BNF (ou d'alternatives sur séquences BNF) comme un symbole BNF. Nous avons ci-dessus l'illustration de deux types de répétition. On peut recenser cinq formes communes :
- apparition optionnelle d'une séquence (ou d'alternatives) : ['-']? signifie que le signe '-' peut ne pas être présent,
- apparition au moins une fois : ['0'..'9']+ signifie qu'on attend une suite non vide de chiffres décimaux,
- absence ou apparition multiple : ['A'..'Z']* signifie qu'on attend un mot en majuscule ou sinon, autre chose qu'une lettre majuscule,
- répétition un nombre fixé de fois : ['#']4 signifie qu'on attend 4 dièses les uns derrière les autres,
- répétition un nombre de fois compris dans un intervalle : ['#']4,6 signifie qu'on attend entre 4 et 6 dièses les uns derrière les autres,
Une grammaire sensée lire un nombre commencera par décrire ce qu'est un nombre. Retouchons notre exemple initial pour que la règle de production d'un nombre se retrouve en tête de grammaire :
nombre ::= flottant | entier;
entier ::= ['-']? ['0'..'9']+;
flottant ::= entier '.' entier ['e' entier]?;
Le reste de cette section vous paraîtra peut-être un peu ardu. Si c'est le cas, n'insistez pas et sautez à la prochaine
section. Vous y reviendrez plus facilement après avoir vu fonctionner les scripts de parsing.
Les règles de production parcourent un texte de la gauche vers la droite, et leurs symboles BNF s'appliquent le plus à
gauche possible (on tente de satisfaire d'abord le premier symbole de la séquence, puis on passe au suivant). Lorsqu'une
séquence BNF échoue, on essaie la prochaine alternative. S'il ne reste plus d'alternatives, on quitte la règle de
production en échec, ce qui fait échouer le symbole non-terminal qui l'a appelé. A son tour, le symbole non-terminal
provoque l'échec de la séquence BNF à laquelle il appartient, et on continue ainsi.
A procéder de la sorte, ce type de parseur est dit à descente récursive et même, plus précisément, LL(k). Le
premier L est là pour rappeler un parcours de la gauche (Left) vers la droite, le second pour signifier qu'on
résoud la règle le plus à gauche possible (Left-most), et le petit k pour dire qu'il peut anticiper plusieurs
coups d'avance (nombre indéterminé k) avant de résoudre une ambiguïté.
CodeWorker ne résoud pas automatiquement une ambiguïté; il faut parfois arranger les règles de production. Pour illustrer
ce que l'on entend pas là, reprenons l'exemple en tête de section. Un nombre est soit un flottant, soit un entier. Or,
un nombre flottant commence toujours par un entier dans notre définition. Donc, si l'on inverse maintenant la règle de
production :
entier ::= ['-']? ['0'..'9']+;
flottant ::= entier '.' entier ['e' entier]?;
l'on va rechercher d'abord un entier, et face à un flottant dans le texte parcouru, on ne lira que sa partie entière puis on sortira en succès du non-terminal nombre.
Conséquence : le non-terminal nombre n'a accompli qu'une partie de sa tâche; il n'a pas récupéré la partie fractionnaire du flottant, et le parsing capotera plus loin, sortant en échec.
Solution : ici, il faut inverser les deux alternatives (donc prendre nombre ::= flottant | entier;).
Ainsi, face à un flottant dans le texte, la première séquence BNF sort en succès tandis que, face à un entier dans le texte, la recherche du flottant échoue et mène à la résolution de l'alternative, qui réussit dans la lecture d'un entier. Nous avons déjà rencontré une extension de la notation Backus-Naur; il s'agit de la répétition (['0'..'9']+ par exemple) et du caractère facultatif d'une séquence de symboles BNF ((['-']? par exemple)). Ils ne sont pas indispensables et peuvent s'exprimer uniquement à l'aide de symboles terminaux et non-terminaux, mariés à l'alternative. En revanche, pour une exploitation concrète efficace, il serait laborieux de ne pas disposer de ces raccourcis pour désigner répétition et optionnalité. Nous allons découvrir d'autres extensions de la BNF, en prenant appui sur l'exemple des sections précédentes que nous enrichissons de quelques règles de production. Exemple :
On veut disposer d'une grammaire qui lit un fichier composé d'une suite de nombres et d'identifiants. Un identifiant commence par une lettre ou un underscore, et poursuit par une séquence de lettres, d'underscores et de chiffres.
contenu_du_fichier ::= [nombre | identifiant]*;
nombre ::= flottant | entier;
entier ::= ['-']? ['0'..'9']+;
flottant ::= entier '.' entier ['e' entier]?;
identifiant ::= [lettre | '_'] [lettre | '0'..'9' | '_']*;
lettre ::= 'a'..'z' | 'A'..'Z';
Dans le fichier texte à lire, ces nombres et identifiants sont séparés par des caractères blancs, genre espaces,
tabulations et retour-chariots. Malheureusement, notre grammaire n'ignore pas ces caractères entre ces symboles
non-terminaux.
Le moment est venu d'introduire la directive #ignore(blanks). Cette directive stipule que, dorénavant,
avant chaque symbole de la séquence BNF à laquelle elle appartient, les caractères blancs seront ignorés automatiquement
par le moteur BNF. La règle de tête devient alors :
nombre ::= flottant | entier;
entier ::= ['-']? ['0'..'9']+;
flottant ::= entier '.' entier ['e' entier]?;
identifiant ::= [lettre | '_'] [lettre | '0'..'9' | '_']*;
lettre ::= 'a'..'z' | 'A'..'Z';
Seulement voilà! L'ignorance des caractères insignifiants se propage dans les règles de production appelées par les symboles non-terminaux nombre et identifiant, et ainsi de suite. Conséquence : on ignore aussi les espaces entre les chiffres d'un entier et les lettres d'un identifiant. Or, c'est erroné : un entier est une série de chiffres contigus, collés les uns aux autres. Il faut donc débrayer localement l'action d'ignorer les blancs au niveau de la définition d'un entier, d'un flottant et d'un identifiant. C'est le rôle de la directive #!ignore. On retouche donc les trois règles :
entier ::= #!ignore ['-']? ['0'..'9']+;
flottant ::= #!ignore entier '.' entier ['e' entier]?;
identifiant ::= #!ignore [lettre | '_'] [lettre | '0'..'9' | '_']*;
A présent, corrigeons la règle de production du nombre flottant, où nous avions volontairement autorisé la partie
fractionnaire à être négative. Il existe un opérateur spécial, noté !symbole-BNF, qui échoue si
le symbole BNF sur lequel il porte est valide, et qui réussit en cas d'échec du symbole BNF. Dans les deux cas, la
règle de production ne progresse absolument pas dans sa lecture. Si l'on emploie une seconde fois cet opérateur (!!symbole-BNF),
il signifie évidemment qu'il réussit si le symbole BNF réussit, et qu'il échoue si le symbole BNF échoue, MAIS sans
jamais progresser dans la lecture. Avantage : cela permet d'accomplir une lecture anticipée (look ahead en anglais) du texte sans déplacer le curseur
de lecture.
flottant ::= #!ignore entier '.' entier ['e' entier]?;
identifiant ::= #!ignore [lettre | '_'] [lettre | '0'..'9' | '_']*;
A présent, employons l'opérateur ! avant de lire la partie fractionnaire, pour nous assurer que cette partie fractionnaire n'est pas négative :
Nous avançons, mais nous n'avons pas encore le moyen de nous assurer que le texte se conforme à la grammaire. En effet, si la grammaire n'arrive pas à s'appliquer sur le fichier texte, l'analyse s'achève en silence. La directive #empty s'assure que la fin du texte a été atteinte. Ce symbole terminal échoue dans le cas contraire. Voici donc la première partie : nous sommes capable de détecter la fin du texte à lire, mais pas encore d'avertir l'utilisateur que tout s'est bien passé. Supposons que nous voulions tracer un message dans la console : nous avons besoin d'insérer un bout de script chargé d'écrire le message. L'insertion d'un bout de script s'annonce par l'opérateur => et est suivie par une instruction terminée par un point-virgule ou suivie par un bloc d'instructions fiché entre accolades. Lorsque le moteur de résolution BNF rencontre ce symbole, il comprend qu'il s'agit là d'une instruction qui ne le concerne pas, et demande son interprétation au moteur de script standard. Voici ce que devient alors notre règle de tête :
contenu_du_fichier ::=
#ignore(blanks) [nombre | identifiant]*
#empty
=> traceLine("L'analyse a réussi!");
;
Si l'analyse aboutit, un message apparaîtra. Mais si elle échoue, comment savoir où cela s'est produit, à
quelle ligne, quelle colonne, pour quelle raison? Pour répondre à toutes ces questions, introduisons la directive
#continue. Placée dans une séquence de symboles BNF, elle impose que le reste de la séquence aboutisse.
#ignore(blanks) [nombre | identifiant]*
#empty
=> traceLine("L'analyse a réussi!");
;
Si un symbole BNF venait à échouer dans la séquence, un message d'erreur serait remontée automatiquement, signalant la ligne et la colonne fautive, ainsi que le symbole BNF en faute. Exemple :
Dans la règle de production d'un nombre flottant, si l'on arrive à lire un entier suivi d'un point, l'on a la certitude de se trouver face à un flottant. Le contraire rèvèlerait une erreur de syntaxe. Il en va de même avec l'exposant : la lettre 'e' annonce un exposant entier.
contenu_du_fichier ::=
#continue
#ignore(blanks) [nombre | identifiant]*
#empty
;
flottant ::= #!ignore entier '.' #continue !'-' entier ['e' #continue entier]?;
Ainsi, si la partie fractionnaire n'est pas composée d'un entier positif, ou si l'exposant n'est pas suivi d'un entier, une
erreur de syntaxe est produite, grace au placement que l'on a fait de la directive #continue. Il en est de même
si l'on n'arrive pas à atteindre la fin de fichier.
L'avantage que l'on peut tirer de l'usage du #continue est de deux natures symétriques. Durant la phase de mise au point,
si vous êtes sûr du fichier texte que vous utilisez pour les tests, si une erreur est remontée, cela signifie que vous
vous êtes trompé dans l'écriture de la grammaire. Durant la phase de production, si vous êtes confiant dans votre grammaire,
cela signifie que le fichier texte lu comporte une erreur de syntaxe. Dans les deux cas, la correction s'avère très rapide
en général, car la pile d'appel des non-terminaux est remontée avec le message d'erreur.
Enrichissons notre grammaire afin d'accepter les chaînes de caractères entre guillemets.
#continue
#ignore(blanks) [nombre | identifiant]*
#empty
;
flottant ::= #!ignore entier '.' #continue !'-' entier ['e' #continue entier]?;
contenu_du_fichier ::=
#continue
#ignore(blanks) [nombre | identifiant | chaine]*
#empty
=> traceLine("L'analyse a réussi!");
;
chaine ::= '"' [~'"']* '"';
// on ne rappelle pas les autres règles de production
L'on a introduit un nouvel opérateur, qui s'écrit ~symbole-BNF. Il est valide et avance de une
position dans la lecture du fichier texte si le symbole BNF échoue. Il échoue et reste sur place si le symbole BNF réussit.
#continue
#ignore(blanks) [nombre | identifiant | chaine]*
#empty
=> traceLine("L'analyse a réussi!");
;
chaine ::= '"' [~'"']* '"';
// on ne rappelle pas les autres règles de production
Dans la règle de production, employé avec la répétition multiple, il signifie que l'on avance d'un cran tant que le guillement final n'a pas été atteint. Il est très fréquent d'utiliser conjointement l'opérateur de négation, que nous venons de découvrir, avec la répétition multiple et la consommation du symbole BNF à atteindre : [~'"']* '"' dans l'exemple précédent, qui signifie d'avancer jusqu'à trouver le guillement, puis le consommer, c'est-à-dire le parcourir. On peut l'exprimer différemment :
sauter juste après le premier guillement rencontré. Cette opération de saut peut s'écrire ->symbole-BNF, et est la forme condensée de [~symbole-BNF]* symbole-BNF. On peut réécrire la règle de production d'une chaine :
Pour l'instant, notre analyse syntaxique s'est bornée à scanner le fichier texte, et n'a pas cherché à extraire l'information utile. Pour récupérer la partie du texte parcourue par un symbole BNF, il suffit de rajouter le nom de la variable à assigner, derrière le symbole et après les avoir séparé par un deux-points. Exemple :
flottant ::=
#!ignore
entier '.' #continue !'-' entier
[
'e' #continue
entier:iExposant
=> traceLine("valeur de l'exposant = " + iExposant);
]?
;
chaine ::=
'"' ->'"':sChaine
=> traceLine(sChaine);
;
Les variables iExposant et sChaine n'ont pas été déclarées préalablement. Elles sont donc créées automatiquement
sur la pile. iExposant a seulement la portée des crochets dans lesquels elle a été déclarée : elle n'est plus
visible une fois sorti de l'optionnalité. En revanche, sChaine a la protée de la règle de production.
Pour la lecture de l'exposant, tout va bien : on a bien la valeur de l'entier. En revanche, il y a un petit souci pour la
chaîne de catactères : l'opérateur de saut lit jusqu'au guillement terminal, que l'on retrouve donc dans la variable
sChaine, alors qu'on ne désirait que le texte inclus entre les guillements. On voudrait réclamer de ne récupérer
que le texte lu jusqu'avant la consommation du guillement terminal. C'est possible en précisant la variable,
précédée de deux-points et encadrée de parenthèses, entre la flêche et le symbole BNF sur lequel sauter.
Ce n'est pas encore parfait, car si la règle de tête récupère dans une variable le texte parcouru par le non-terminal
chaine, elle se retrouvera en présence des guillemets initiaux et finaux. Heureusement, on peut construire soi-même
la valeur que doit retourner une règle de production. Le nom de la règle doit être suivi de value après deux-points,
et la valeur doit être affectée à une variable qui a le nom de la règle.
#!ignore
entier '.' #continue !'-' entier
[
'e' #continue
entier:iExposant
=> traceLine("valeur de l'exposant = " + iExposant);
]?
;
chaine ::=
'"' ->'"':sChaine
=> traceLine(sChaine);
;
// seul le coeur de la chaine sera retourné par la règle de production
chaine : value ::= '"' ->(:chaine)'"';
Nous savons maintenant récupérer localement des fragments de texte, ceux qui nous paraissent pertinents. Il ne nous reste
plus qu'à les ranger dans une structure de données. Voyons comment procéder à partir de notre exemple, que nous allons
retravailler.
On considère nos fichiers texte comme une suite d'éléments. Un élément est soit un nombre, soit un identifiant, soit une
chaîne. On veut ranger dans une liste la séquence d'éléments que nous avons extraites.
chaine : value ::= '"' ->(:chaine)'"';
contenu_du_fichier ::=
#continue
#ignore(blanks)
#continue
[
#pushItem(this)
element(this#back)
]*
#empty
;
element(item : node) ::=
nombre:dValeur
=> insert item.type = "nombre";
=> insert item.value = dValeur;
|
identifiant:sId
=> insert item.type = "identifiant";
=> insert item.value = sId;
|
chaine:sChaine
=> insert item.type = "chaine";
=> insert item.value = sChaine;
;
Epluchons à présent cet exemple. Lorsqu'un script BNF s'exécute, il ne voit pas le scope des variables du script qui
l'a lancé. Notamment, il ne sait pas quelle variable renseigner avec les fagments de texte qu'il aura extraits du fichier.
#continue
#ignore(blanks)
#continue
[
#pushItem(this)
element(this#back)
]*
#empty
;
element(item : node) ::=
nombre:dValeur
=> insert item.type = "nombre";
=> insert item.value = dValeur;
|
identifiant:sId
=> insert item.type = "identifiant";
=> insert item.value = sId;
|
chaine:sChaine
=> insert item.type = "chaine";
=> insert item.value = sChaine;
;
C'est pourquoi, chaque fois qu'on lance un script de parsing BNF, avec la procédure parseAsBNF(script, variable, fichier_texte), on lui passe le nom de la variable à renseigner. C'est le deuxième paramètre de la procédure. A l'intérieur du script de parsing BNF, cette variable s'appelle this dans tous les cas, et représente le contexte que l'appelant a bien voulu lui soumettre. Nous voulons renseigner la variable this avec une liste d'éléments. La directive #pushItem(liste) rajoute un élement dans la liste passée en paramètre : dans la table d'association, un nouvel élément est inséré avec un indice entier comme valeur de la clé. L'indice commence à compter à partir de zéro, et s'incrémente. Si la séquence BNF à laquelle appartient la directive échoue, l'élément est automatiquement supprimé de la liste. La règle de production element se charge de remplir ce nouvel élément de la liste. Pour ce faire, il est passé en paramètre à la règle de production, qui attend un argument passé par référence (le mode de passage par référence est node, comme pour les fonctions). Supposons à présent que nous voulions écrire une grammaire capable de lire la description de jouets et de desserts du genre :
- chaque jouet appartient à une catégorie et détaille son alimentation (type, taille, quantité),
- chaque dessert appartient à une famille, utilise un type de pate et a une garniture simple ou multiple,
$TMP/Developpez.com/objets.txt
dessert "tartelette"
pate "sablee"
garniture 2
"fraise" 8
"abricot" 0.5
jouet
categorie "voiture"
alimentation "piles"
quantite 4
taille "LR6"
Vu l'état actuel de nos connaissances sur CodeWorker, on écrirait notre grammaire ainsi :
pate "sablee"
garniture 2
"fraise" 8
"abricot" 0.5
jouet
categorie "voiture"
alimentation "piles"
quantite 4
taille "LR6"
objets ::=
#ignore(blanks)
#continue
[jouet | dessert]*
#empty
;
jouet ::=
"jouet"
#continue
"categorie" chaine
"alimentation" chaine
"quantite" entier
"taille" chaine
;
dessert ::=
"dessert"
#continue
chaine
"pate" chaine
"garniture" entier
[chaine #continue nombre]+
;
// Il faut inclure ici les règles de production 'chaine', 'nombre',
// 'entier' et 'flottant'
Cette grammaire ne décrit pas tout à fait ce que nous voulons. En effet, elle n'est pas capable de tétecter une erreur de
syntaxe si le fichier texte ne comprend pas de blancs entre jouet et categorie, que les deux mots
soient attachés pour former jouetcategorie. Il aurait fallu écrire que l'on voulait lire un identifiant valant
valant jouet exactement. Cela se note identifiant:"jouet".
Supposons à présent que la taille des piles soit à prendre parmi LR3, LR4 et LR6, et que l'on veuille la récupérer dans une
variable. On écrit cela ainsi : chaine:{"LR3", "LR4", "LR6"}:sTaille.
#ignore(blanks)
#continue
[jouet | dessert]*
#empty
;
jouet ::=
"jouet"
#continue
"categorie" chaine
"alimentation" chaine
"quantite" entier
"taille" chaine
;
dessert ::=
"dessert"
#continue
chaine
"pate" chaine
"garniture" entier
[chaine #continue nombre]+
;
// Il faut inclure ici les règles de production 'chaine', 'nombre',
// 'entier' et 'flottant'
La règle de production intègre maintenant ces deux ajustements :
jouet ::=
identifiant:"jouet"
#continue
"categorie" chaine
"alimentation" chaine
"quantite" entier
"taille" chaine:{"LR3", "LR4", "LR6"}:sTaille
=> traceLine("taille = " + sTaille);
;
On s'aperçoit alors que les attributs taille et quantite n'ont un sens que si l'alimentation du jouet se
fait par piles. Il existe la directive #check(expression), qui réussit si l'expression booléenne est
valide, et qui échoue dans le cas contraire.
identifiant:"jouet"
#continue
"categorie" chaine
"alimentation" chaine
"quantite" entier
"taille" chaine:{"LR3", "LR4", "LR6"}:sTaille
=> traceLine("taille = " + sTaille);
;
jouet ::=
identifiant:"jouet"
#continue
"categorie" chaine
"alimentation" chaine:sAlimentation
[
#check(sAlimentation == "piles")
#continue
"quantite" entier
"taille" chaine:{"LR3", "LR4", "LR6"}:sTaille
=> traceLine("taille = " + sTaille);
]?
;
Supposons à présent qu'il soit fréquent d'enrichir ce format de nouveaux attributs, et parfois même, de nouveaux
objets. Il peut devenir difficile de maintenir la grammaire à jour. Heureusement, il existe un moyen de détecter lorsque
la grammaire tombe sur un attribut qu'elle ne sait pas encore traiter. Cela se fait grâce aux règles de production
génériques instantiées, dont voici un exemple :
identifiant:"jouet"
#continue
"categorie" chaine
"alimentation" chaine:sAlimentation
[
#check(sAlimentation == "piles")
#continue
"quantite" entier
"taille" chaine:{"LR3", "LR4", "LR6"}:sTaille
=> traceLine("taille = " + sTaille);
]?
;
dessert ::=
"dessert"
#continue
chaine
[
identifiant:sAttribut
dessert_attribut<sAttribut>
]+
;
dessert_attribut<"pate"> ::= #continue chaine;
dessert_attribut<"garniture"> ::=
#continue entier
[chaine #continue nombre]+
;
Ici, la règle de production dessert_attribut connaît plusieurs implémentations, qui varient selon la valeur prise
par une chaîne de caractères placée entre < ... >. La règle de production dessert_attribut<"pate">
est une instantiation possible de la règle de production générique dessert_attribut<T>, que nous n'implémenterons pas ici.
Comment cela fonctionne-t-il ? Le non-terminal dessert_attribut<sAttribut> appelle la bonne instantiation de
cette règle, dépendant de la valeur prise par sAttribut : "pate" ou "garniture". Si la valeur
prise par sAttribut ne vaut ni l'une ni l'autre, l'implémentation générique de cette règle est appelée. Comme
nous ne l'implémenterons pas, une erreur est produite à l'exécution, qui précise qu'il n'a pas su instantier de règle de
production sur dessert_attribut<sAttribut> pour la valeur passée.
Si l'on rajoute l'attribut thermostat dans le fichier texte, l'interpréteur déclenchera un message d'erreur lorsqu'il
le rencontrera, précisant qu'il n'y a aucune forme de dessert_attribut<sAttribut> capable de s'instantier sur "thermostat".
"dessert"
#continue
chaine
[
identifiant:sAttribut
dessert_attribut<sAttribut>
]+
;
dessert_attribut<"pate"> ::= #continue chaine;
dessert_attribut<"garniture"> ::=
#continue entier
[chaine #continue nombre]+
;
Le développeur n'a alors plus qu'à rajouter l'implémentation de la règle de production dessert_attribut<"thermostat">. Il existe quelques règles de production qui reviennent très souvent, comme la lecture d'un entier, d'un flottant, d'une chaîne de caractères, d'un identifiant ... et quelques autres encore. Pour celles-ci, CodeWorker propose des symboles non-terminaux prédéfinis, dont la règle est codée en dur. Dans le vocabulaire propre à CodeWorker, elles s'appellent des directives pseudo-terminales, car elles s'apparentent à des symboles BNF terminaux puisque leur règle de production est invisible. En voici quelques unes:
| Directive | Usage |
| #readIdentifer | Lit un identifiant. |
| #readInteger | Lit un entier. |
| #readNumeric | Lit un nombre, entier ou flottant. |
| #readCString | Lit une chaîne de caractères entre guillemets, et acceptant les caractères d'échappement du C. Sa particularité est de ne retourner que le corps de la chaîne, sans les guillements, à la manière de la règle de production chaine dans nos exemples. |
| #readText(expression) | Evalue l'expression passée en paramètre, et lit son résultat. |
$TMP/Developpez.com/objets-scanner.cwp
codeworker $TMP/Developpez.com/objets-scanner.cwp $TMP/Developpez.com/objets.txt -nologo
objets ::=
#ignore(blanks)
#continue
[#readIdentifier:sObjet #continue objet<sObjet>]*
#empty
;
objet<"jouet"> ::=
#continue
[
#readIdentifier:sAttribut
jouet_attribut<sAttribut>
]+
;
jouet_attribut<"categorie"> ::= #continue #readCString;
jouet_attribut<"alimentation"> ::=
#continue
#readCString:sAlimentation
[
#check(sAlimentation == "piles")
"quantite" #readInteger
"taille" #readCString:{"LR3", "LR4", "LR6"}:sTaille
]?
;
jouet_attribut<T> ::= #check(false);
objet<"dessert"> ::=
#continue
#readCString
[
#readIdentifier:sAttribut
dessert_attribut<sAttribut>
]+
;
dessert_attribut<"pate"> ::= #continue #readCString;
dessert_attribut<"garniture"> ::=
#continue #readInteger
[#readCString #continue #readNumeric]+
;
dessert_attribut<T> ::= #check(false);
On notera l'ajout de deux règles de production génériques, une sur la reconnaissance des attributs d'un jouet
et l'autre sur les attributs d'un dessert.
#ignore(blanks)
#continue
[#readIdentifier:sObjet #continue objet<sObjet>]*
#empty
;
objet<"jouet"> ::=
#continue
[
#readIdentifier:sAttribut
jouet_attribut<sAttribut>
]+
;
jouet_attribut<"categorie"> ::= #continue #readCString;
jouet_attribut<"alimentation"> ::=
#continue
#readCString:sAlimentation
[
#check(sAlimentation == "piles")
"quantite" #readInteger
"taille" #readCString:{"LR3", "LR4", "LR6"}:sTaille
]?
;
jouet_attribut<T> ::= #check(false);
objet<"dessert"> ::=
#continue
#readCString
[
#readIdentifier:sAttribut
dessert_attribut<sAttribut>
]+
;
dessert_attribut<"pate"> ::= #continue #readCString;
dessert_attribut<"garniture"> ::=
#continue #readInteger
[#readCString #continue #readNumeric]+
;
dessert_attribut<T> ::= #check(false);
En effet, vue la syntaxe choisie pour décrire nos objets, lorsqu'on rencontre un identifiant, il y a ambiguïté entre nouvel attribut ou nouvel objet. Ainsi, lorsqu'un attribut ne se retrouve aiguillé sur aucune des règles de production instantiées pour leur traitement, il est récupéré par la règle générique qui simplement échoue. Sans cette règle, une erreur interromprait l'exécution, alors que l'identifiant annonce simplement un nouvel objet, traité plus loin par les règles objet<"dessert"> ou objet<"jouet">. Nous avons à présent toutes les informations en main pour construire le graphe de parsing à la lecture du texte. Voici ce que devient notre exemple :
$TMP/Developpez.com/objets.cwp
codeworker $TMP/Developpez.com/objets.cwp $TMP/Developpez.com/objets.txt -nologo
objets ::=
#ignore(blanks)
#continue
[#readIdentifier:sObjet #continue objet<sObjet>]*
#empty
=> saveProject(getEnv("TMP") + "/Developpez.com/objets.xml");
;
objet<"jouet"> ::=
#continue
=> pushItem this.jouets;
=> ref jouet = this.jouets#back;
[
#readIdentifier:sAttribut
jouet_attribut<sAttribut>(jouet)
]+
;
jouet_attribut<"categorie">(jouet : node) ::= #continue #readCString:jouet.categorie;
jouet_attribut<"alimentation">(jouet : node) ::=
#continue
#readCString:jouet.alimentation
[
#check(jouet.alimentation == "piles")
#continue
"quantite" #readInteger:jouet.alimentation.quantite
"taille" #readCString:{"LR3", "LR4", "LR6"}:jouet.alimentation.taille
]?
;
jouet_attribut<T>(jouet : node) ::= #check(false);
objet<"dessert"> ::=
#continue
=> pushItem this.desserts;
=> ref dessert = this.desserts#back;
#readCString:dessert
[
#readIdentifier:sAttribut
dessert_attribut<sAttribut>(dessert)
]+
;
dessert_attribut<"pate">(dessert : node) ::= #continue #readCString:dessert.pate;
dessert_attribut<"garniture">(dessert : node) ::=
#continue #readInteger:iNb
[
#readCString:sFruit
#continue
#readNumeric:dessert.garniture[sFruit]
]+
// on s'assure que le nombre de garnitures est bien celui annoncé
#check($dessert.garniture.size() == iNb$)
;
dessert_attribut<T>(dessert : node) ::= #check(false);
Nous remarquerons dans la règle de tête que le graphe du projet est sauvé dans un fichier XML par la fonction
saveProject(). Voici un exemple de graphe obtenu par cette fonction, après
exécution sur le fichier texte présenté en début de chapitre.
#ignore(blanks)
#continue
[#readIdentifier:sObjet #continue objet<sObjet>]*
#empty
=> saveProject(getEnv("TMP") + "/Developpez.com/objets.xml");
;
objet<"jouet"> ::=
#continue
=> pushItem this.jouets;
=> ref jouet = this.jouets#back;
[
#readIdentifier:sAttribut
jouet_attribut<sAttribut>(jouet)
]+
;
jouet_attribut<"categorie">(jouet : node) ::= #continue #readCString:jouet.categorie;
jouet_attribut<"alimentation">(jouet : node) ::=
#continue
#readCString:jouet.alimentation
[
#check(jouet.alimentation == "piles")
#continue
"quantite" #readInteger:jouet.alimentation.quantite
"taille" #readCString:{"LR3", "LR4", "LR6"}:jouet.alimentation.taille
]?
;
jouet_attribut<T>(jouet : node) ::= #check(false);
objet<"dessert"> ::=
#continue
=> pushItem this.desserts;
=> ref dessert = this.desserts#back;
#readCString:dessert
[
#readIdentifier:sAttribut
dessert_attribut<sAttribut>(dessert)
]+
;
dessert_attribut<"pate">(dessert : node) ::= #continue #readCString:dessert.pate;
dessert_attribut<"garniture">(dessert : node) ::=
#continue #readInteger:iNb
[
#readCString:sFruit
#continue
#readNumeric:dessert.garniture[sFruit]
]+
// on s'assure que le nombre de garnitures est bien celui annoncé
#check($dessert.garniture.size() == iNb$)
;
dessert_attribut<T>(dessert : node) ::= #check(false);
 Nous n'allons pas faire preuve d'originalité, et nous ramener sur les préoccupations de la plupart des développeurs en
entreprise d'aujourd'hui : nous allons produire des objets. Nous considérerons qu'une tierce partie nous fournit une
IDL CORBA, qu'ils sont susceptibles de changer à tout moment. Derrière, nous devrons intégrer leurs évolutions dans
les délais les plus courts, sans perdre en robustesse.
Nous n'allons pas faire preuve d'originalité, et nous ramener sur les préoccupations de la plupart des développeurs en
entreprise d'aujourd'hui : nous allons produire des objets. Nous considérerons qu'une tierce partie nous fournit une
IDL CORBA, qu'ils sont susceptibles de changer à tout moment. Derrière, nous devrons intégrer leurs évolutions dans
les délais les plus courts, sans perdre en robustesse.
| IDL et CORBA |
| Rappelons très brièvement que CORBA définit une norme de distribution des objets et d'appel à des requêtes distantes dans une architecture dite 3-tiers : applications clientes, bus logiciel pour la circulation des objets et requêtes, applications serveurs. Une IDL (Interface Definition Language) spécifie l'interface des objets à échanger (méthodes et attributs), sans présager de l'implantation qui en sera faite sur le client ou sur le serveur. Ainsi, une application cliente Java pourra appeler des méthodes sur des objets distants implantés en C++ sur une application serveur, du moment que les deux se conforment à l'IDL. Concrètement et pour faire vite, une IDL ressemble beaucoup à une déclaration de classe C++, mise à part les mots-clés qui diffèrent (module pour namespace par exemple). |
$TMP/Developpez.com/videostore.idl
#ifndef _videostore_idl_
#define _videostore_idl_
interface Produit {
double Prix;
};
typedef sequence<Produit> Produits;
interface Figurine : Produit {
string Nom;
double Poids;
};
typedef sequence<string> Acteurs;
struct SynopsisFilm {
string Titre;
string MetteurEnScene;
Acteurs Acteurs;
long DureeEnMinutes;
};
interface DVD : Produit {
boolean DestineLocation;
SynopsisFilm Synopsis;
};
interface HomeCinema : Produit {
double DestineLocation;
};
struct Client {
string Nom;
string Adresse;
string Carte;
};
typedef sequence<Client> Clients;
struct BonDeLocation {
Client Client;
Produit Produit;
string DateRetour;
double Prix;
};
typedef sequence<BonDeLocation> BonsDeLocation;
interface Magasin {
readonly string Nom;
readonly string Adresse;
Clients Clients;
Produits Produits;
};
interface Videostore : Magasin {
readonly BonsDeLocation StockSorti;
BonDeLocation loue(in Client client, in Produit produit, in long dureeHoraire);
void achete(in Client client, in Produit produit, in long Quantite);
};
#endif
De ce fichier IDL, nous voulons récupérer les interfaces et leurs membres, les structures et leurs attributs, les
exceptions et les typedefs. Plus tard, nous nous servirons de cette information pour alimenter la génération de
code.
Nous ne nous lancerons pas dans l'écriture d'un parseur IDL : seules certaines informations nous intéressent. De plus, on
considèrera que la tierce partie n'utilisera jamais les enums, les modules ou les exceptions,
et que les typedefs ne serviront pas autrement que pour déclarer des séquences d'objets. Les types
de base seront parmi boolean, long, double et string. Toujours
pour simplifier, nous ne prenons pas en compte le préprocesseur C (les directives commençant par un dièse et les
macros), dont les directives ne seront présentes qu'en début ou en fin de fichier.
Voici à quoi pourrait ressembler l'analyseur syntaxique de ce type de fichiers, sans construction du graphe :
#define _videostore_idl_
interface Produit {
double Prix;
};
typedef sequence<Produit> Produits;
interface Figurine : Produit {
string Nom;
double Poids;
};
typedef sequence<string> Acteurs;
struct SynopsisFilm {
string Titre;
string MetteurEnScene;
Acteurs Acteurs;
long DureeEnMinutes;
};
interface DVD : Produit {
boolean DestineLocation;
SynopsisFilm Synopsis;
};
interface HomeCinema : Produit {
double DestineLocation;
};
struct Client {
string Nom;
string Adresse;
string Carte;
};
typedef sequence<Client> Clients;
struct BonDeLocation {
Client Client;
Produit Produit;
string DateRetour;
double Prix;
};
typedef sequence<BonDeLocation> BonsDeLocation;
interface Magasin {
readonly string Nom;
readonly string Adresse;
Clients Clients;
Produits Produits;
};
interface Videostore : Magasin {
readonly BonsDeLocation StockSorti;
BonDeLocation loue(in Client client, in Produit produit, in long dureeHoraire);
void achete(in Client client, in Produit produit, in long Quantite);
};
#endif
$TMP/Developpez.com/videostore-scanner.cwp
codeworker $TMP/Developpez.com/videostore-scanner.cwp $TMP/Developpez.com/videostore.idl -nologo
// la règle de tête : lecture de tout le fichier IDL, jusqu'à atteindre la fin de fichier
idl_parser ::=
#ignore(C++)
#continue
[
// On passe sur les directives du préprocesseur placées
// entre les déclarations de premier niveau.
// En gros, cela permet au moins de supprimer les directives
// positionnées au début ou à la fin du fichier.
'#' #!ignore ->'\n'
|
declaration
]*
#empty
;
// une déclaration est amorcée par un mot-clé : "module", "struct",
// "typedef" ou "interface". En fonction de ce mot-clé, on appellera la bonne
// instantiation de fonction générique.
declaration ::=
#readIdentifier:sDecl
declaration<sDecl>
;
// déclaration d'une structure : se limite ici à contenir des attributs
declaration<"struct"> ::=
#continue
identifier // nom de la structure
'{'
[attribute_declaration]*
'}'
';'
;
// déclaration d'un typedef : c'est une sorte d'alias, expression raccourcie d'un type
declaration<"typedef"> ::=
// ici, on ne s'intéressera qu'aux alias sur les séquences d'objets ou
// de types de base
"sequence"
'<'
type_name
'>'
identifier // nom de l'alias
';'
|
// ce n'est pas une séquence, donc on ignore ce 'typedef'
->';'
;
declaration<"interface"> ::=
#continue
identifier // nom de l'interface
[
':' #continue
identifier // nom du parent
]?
'{'
[member_declaration]*
'}'
';'
;
// un membre d'une interface est soit un attribut, soit une méthode
member_declaration ::= attribute_declaration | method_declaration;
// définition d'un attribut, que l'on retrouve dans une interface, une struct ou une exception :
attribute_declaration ::=
[#readIdentifier:"readonly"]?
type_name
identifier // nom de l'attribut
';'
;
// définition d'une méthode
method_declaration ::=
// type de retour de la méthode
[type_name | #readIdentifier:"void"]
identifier // nom de la méthode
'('
// à partir de là, on est sûr d'avoir affaire à une méthode :
// tout le reste de la séquence BNF doit être valide
#continue
[
// paramètres de la méthode, s'il y en a
parameter
[',' #continue parameter]*
]?
')'
';'
;
// paramètre de méthode
parameter ::=
// mode de passage du paramètre, mot-clé parmi trois possibles
#readIdentifier:{"in", "inout", "out"}
type_name // type du paramètre
identifier // nom du paramètre
;
// nom d'un type, qui peut être un alias de "typedef', un type de base,
// une structure ou une interface
type_name ::= #readIdentifier;
identifier:value ::=
#readIdentifier:identifier
// un identifiant ne peut pas être un mot-clé du langage
#check(!(identifier in {"abstract", "any", "attribute", "boolean", "case", "char",
"component", "const", "consults", "context", "custom", "default", "double", "emits",
"enum", "eventtype", "exception", "factory", "FALSE", "finder", "fixed", "float",
"getraises", "home", "import", "in", "inout", "interface", "local", "long",
"manages", "module", "multiple", "native", "Object", "octet", "oneway", "out",
"primarykey", "private", "provides", "public", "publishes", "raises", "readonly",
"sequence", "setraises", "short", "string", "struct", "supports", "switch", "TRUE",
"truncatable", "typedef", "typeid", "typeprefix", "union", "unsigned", "uses",
"ValueBase", "valuetype", "wchar", "wstring"}))
;
Si à l'avenir, nous voulions prendre en compte les déclarations de modules ou d'exceptions, nous aurions juste à rajouter :
idl_parser ::=
#ignore(C++)
#continue
[
// On passe sur les directives du préprocesseur placées
// entre les déclarations de premier niveau.
// En gros, cela permet au moins de supprimer les directives
// positionnées au début ou à la fin du fichier.
'#' #!ignore ->'\n'
|
declaration
]*
#empty
;
// une déclaration est amorcée par un mot-clé : "module", "struct",
// "typedef" ou "interface". En fonction de ce mot-clé, on appellera la bonne
// instantiation de fonction générique.
declaration ::=
#readIdentifier:sDecl
declaration<sDecl>
;
// déclaration d'une structure : se limite ici à contenir des attributs
declaration<"struct"> ::=
#continue
identifier // nom de la structure
'{'
[attribute_declaration]*
'}'
';'
;
// déclaration d'un typedef : c'est une sorte d'alias, expression raccourcie d'un type
declaration<"typedef"> ::=
// ici, on ne s'intéressera qu'aux alias sur les séquences d'objets ou
// de types de base
"sequence"
'<'
type_name
'>'
identifier // nom de l'alias
';'
|
// ce n'est pas une séquence, donc on ignore ce 'typedef'
->';'
;
declaration<"interface"> ::=
#continue
identifier // nom de l'interface
[
':' #continue
identifier // nom du parent
]?
'{'
[member_declaration]*
'}'
';'
;
// un membre d'une interface est soit un attribut, soit une méthode
member_declaration ::= attribute_declaration | method_declaration;
// définition d'un attribut, que l'on retrouve dans une interface, une struct ou une exception :
attribute_declaration ::=
[#readIdentifier:"readonly"]?
type_name
identifier // nom de l'attribut
';'
;
// définition d'une méthode
method_declaration ::=
// type de retour de la méthode
[type_name | #readIdentifier:"void"]
identifier // nom de la méthode
'('
// à partir de là, on est sûr d'avoir affaire à une méthode :
// tout le reste de la séquence BNF doit être valide
#continue
[
// paramètres de la méthode, s'il y en a
parameter
[',' #continue parameter]*
]?
')'
';'
;
// paramètre de méthode
parameter ::=
// mode de passage du paramètre, mot-clé parmi trois possibles
#readIdentifier:{"in", "inout", "out"}
type_name // type du paramètre
identifier // nom du paramètre
;
// nom d'un type, qui peut être un alias de "typedef', un type de base,
// une structure ou une interface
type_name ::= #readIdentifier;
identifier:value ::=
#readIdentifier:identifier
// un identifiant ne peut pas être un mot-clé du langage
#check(!(identifier in {"abstract", "any", "attribute", "boolean", "case", "char",
"component", "const", "consults", "context", "custom", "default", "double", "emits",
"enum", "eventtype", "exception", "factory", "FALSE", "finder", "fixed", "float",
"getraises", "home", "import", "in", "inout", "interface", "local", "long",
"manages", "module", "multiple", "native", "Object", "octet", "oneway", "out",
"primarykey", "private", "provides", "public", "publishes", "raises", "readonly",
"sequence", "setraises", "short", "string", "struct", "supports", "switch", "TRUE",
"truncatable", "typedef", "typeid", "typeprefix", "union", "unsigned", "uses",
"ValueBase", "valuetype", "wchar", "wstring"}))
;
// déclaration d'un module : peut contenir toutes sortes de déclarations
declaration<"module"> ::=
#continue
identifier // nom du module
'{'
[declaration]*
'}'
';'
;
// déclaration d'une exception : se limite ici à contenir des attributs
declaration<"exception"> ::=
#continue
identifier // nom de l'exception
'{'
[attribute_declaration]*
'}'
';'
;
Ceci illustre bien la capacité des règles de production génériques à enrichir la grammaire sans se préoccuper de savoir
qui aura besoin d'appeler le nouveau symbole non-terminal.
Nous n'allons pas consommer un espace inutile au coeur de ce document pour vous présenter ce à quoi pourrait ressembler
le parseur. Nous vous proposons plutôt de suivre le lien.
Si vous souhaitez passer directement à la génération de code appliquée sur ce projet, sans préalablement suivre la
formation sur les modèles de générations, sautez directement à la dernière section du
chapitre suivant.
L'analyseur syntaxique est un travailleur de l'ombre, dont la fonction se réduit souvent à nourrir le générateur de code. Sa
tâche est fondamentale, mais c'est la génération de code qui recueille tous les lauriers. Il est évident qu'au final, le
développeur attend de l'outil qu'il produise du code source ou, plus généralement, du texte. Ce code généré est ce qu'il
n'aura pas à taper lui-même.
CodeWorker distingue deux manières de générer un fichier. La première, classique, consiste à réécrire complètement le
fichier, après préservation éventuelle du code tapé à la main. La seconde consiste à injecter du code à certains endroits
seulement d'un fichier existant, et est appelée expansion de code dans le vocabulaire de CodeWorker. Ces deux
approches sont opposées. La plus riche est sans nulle doute l'expansion de code.
Un modèle de génération de code est un script qui mêle à la fois du texte brut tel qu'on veut le voir figurer dans
le fichier à construire, des instructions à interpréter et des expressions du langage de script dont les évaluations sont
à recopier directement dans le fichier. Ceux qui ont approché de près ou de loin PHP ou JSP connaissent le principe de
ces scripts, que les anglo-saxons désignent par template-based scripts.
Voici un exemple de modèle de génération chargée de produire une classe Java pour l'objet jouet, déjà croisé
dans le chapitre consacré à l'analyse syntaxique :
declaration<"module"> ::=
#continue
identifier // nom du module
'{'
[declaration]*
'}'
';'
;
// déclaration d'une exception : se limite ici à contenir des attributs
declaration<"exception"> ::=
#continue
identifier // nom de l'exception
'{'
[attribute_declaration]*
'}'
';'
;
$TMP/Developpez.com/jouet.java.cwt
package org.tutorial.examples;
public class @this.categorie@ extends Jouet {
public String alimentation() { return "@this.alimentation@"; }
<%
if this.alimentation == "piles" {
@ public int piles() { return "@this.alimentation.quantite@"; }
public String typeDePile() { return "@this.alimentation.taille@"; }
@
}
%>
public void jouer() {
}
}
@
Les parties écrites sur fond jaune mettent en valeur le texte brut tel qu'il sera recopié dans le fichier à générer. On notera
que l'on démarre d'office en mode texte brut. L'arobas @ signale un basculement entre
les modes texte brut et interprétation de script, ou l'inverse.
public class @this.categorie@ extends Jouet {
public String alimentation() { return "@this.alimentation@"; }
<%
if this.alimentation == "piles" {
@ public int piles() { return "@this.alimentation.quantite@"; }
public String typeDePile() { return "@this.alimentation.taille@"; }
@
}
%>
public void jouer() {
}
}
@
Il existe aussi les symboles <% et %> qui présentent l'avantage d'être mono-directionnels, et dont l'on ressent les bienfaits à la relecture d'un modèle de génération sans coloration syntaxique :
- <% : basculement en mode interprétation de script,
- %> : basculement en mode texte brut,
$TMP/Developpez.com/objets.txt
dessert "tartelette"
pate "sablee"
garniture 2
"fraise" 8
"abricot" 0.5
jouet
categorie "voiture"
alimentation "piles"
quantite 4
taille "LR6"
Nous allons créer une classe Java pour chaque catégorie de jouet rencontrée, qui implantera ses propres
accesseurs aux caractéristiques de l'alimentation. Pour ce faire, nous allons taper quelques lignes d'un script chargé
d'extraire la description des objets, de parcourir l'ensemble des jouets et de générer une classe pour chacun d'eux.
pate "sablee"
garniture 2
"fraise" 8
"abricot" 0.5
jouet
categorie "voiture"
alimentation "piles"
quantite 4
taille "LR6"
$TMP/Developpez.com/jouets.java.cws
codeworker $TMP/Developpez.com/jouets.java.cws -nologo
parseAsBNF(getEnv("TMP") + "/Developpez.com/objets.cwp", project,
getEnv("TMP") + "/Developpez.com/objets.txt");
foreach i in project.jouets {
generate(getEnv("TMP") + "/Developpez.com/jouet.java.cwt",
i,
getEnv("TMP") + "/Developpez.com/org/tutorial/examples/" + i.categorie + ".java");
}
La procédure parseAsBNF() applique l'exécution d'un script BNF étendu sur
un fichier texte. Le script remplit le graphe project passé en deuxième paramètre de la
procédure.
La procédure generate() génère un fichier texte à partir du modèle de génération
de code passé en premier paramètre. Le script explore le graphe qui lui est passé en deuxième paramètre, et qu'il appelle
this. Ici, le graphe est le jouet courant à traiter, l'information utile au modèle de
génération en quelque sorte.
Voici le résultat obtenu :
getEnv("TMP") + "/Developpez.com/objets.txt");
foreach i in project.jouets {
generate(getEnv("TMP") + "/Developpez.com/jouet.java.cwt",
i,
getEnv("TMP") + "/Developpez.com/org/tutorial/examples/" + i.categorie + ".java");
}
$TMP/Developpez.com/org/tutorial/examples/voiture.java
package org.tutorial.examples;
public class voiture extends Jouet {
public String alimentation() { return "piles"; }
public int piles() { return "4"; }
public String typeDePile() { return "LR6"; }
public void jouer() {
}
}
A présent, implémentons la méthode jouer(). Son implémentation dépendra de la nature du jouet. La classe
voiture doit par exemple décrire son propre comportement. Pour elle, l'algorithme peut ressembler à : tourner
deux-trois fois, s'aligner dans le couloir, mettre les gaz, percuter une plinthe ou le mur du fond, et recommencer du début
tant que l'essieu avant ne s'est pas rompu. On aura compris qu'il s'agit de simuler ici le comportement d'un enfant de 5 ans.
public class voiture extends Jouet {
public String alimentation() { return "piles"; }
public int piles() { return "4"; }
public String typeDePile() { return "LR6"; }
public void jouer() {
}
}
$TMP/Developpez.com/org/tutorial/examples/voiture.java
...
public void jouer() {
do {
tourneAleatoirement(3/*fois*/);
aligneVehicule();
metGaz();
constateSortieDeRoute();
} while (essieuValide());
}
...
Beaucoup plus tard, après avoir changé votre fichier de description ou votre modèle de génération de code, vous décidez de
relancer la génération de code ... et voici le résultat :
public void jouer() {
do {
tourneAleatoirement(3/*fois*/);
aligneVehicule();
metGaz();
constateSortieDeRoute();
} while (essieuValide());
}
...
$TMP/Developpez.com/org/tutorial/examples/voiture.java
...
public void jouer() {
}
...
Vous avez tout perdu! La génération de code classique réécrit entièrement le fichier à générer. Là, l'outil n'avait aucun
moyen de savoir qu'il fallait attacher une attention particulière au contenu de la méthode. Et pourtant, il existe un moyen
de préserver du code tapé à la main : introduire une zône de code protégée dans le corps de la méthode au moment de la
génération. C'est le rôle de la procédure setProtectedArea() :
public void jouer() {
}
...
$TMP/Developpez.com/jouet.java.cwt
package org.tutorial.examples;
public class @this.categorie@ extends Jouet {
public String alimentation() { return "@this.alimentation@"; }
<%
if this.alimentation == "piles" {
@ public int piles() { return "@this.alimentation.quantite@"; }
public String typeDePile() { return "@this.alimentation.taille@"; }
@
}
%>
public void jouer() {
@
setProtectedArea("corps de la méthode 'jouer()'");
@ }
}
@
La procédure setProtectedArea() prend une chaîne de caractères en paramètre. Le
texte est libre; il servira de clé pour identifier la zône de code protégée de manière unique dans le fichier généré.
public class @this.categorie@ extends Jouet {
public String alimentation() { return "@this.alimentation@"; }
<%
if this.alimentation == "piles" {
@ public int piles() { return "@this.alimentation.quantite@"; }
public String typeDePile() { return "@this.alimentation.taille@"; }
@
}
%>
public void jouer() {
@
setProtectedArea("corps de la méthode 'jouer()'");
@ }
}
@
Voici le résultat :
codeworker $TMP/Developpez.com/jouets.java.cws -nologo
$TMP/Developpez.com/org/tutorial/examples/voiture.java
package org.tutorial.examples;
public class voiture extends Jouet {
public String alimentation() { return "piles"; }
public int piles() { return "4"; }
public String typeDePile() { return "LR6"; }
public void jouer() {
//##protect##"corps de la méthode 'jouer()'"
//##protect##"corps de la méthode 'jouer()'"
}
}
La zône de code protégée se situe entre les deux balises //##protect##"corps de la méthode 'jouer()'" . Tout
code tapé à la main dans cette portion sera préservé d'une génération à l'autre. Si le setProtectedArea("corps de la méthode 'jouer()'")
disparaissait, la zône de code protégée, ne trouvant plus d'ancrage lors de la génération suivante, serait rejetée à la
fin du fichier. Lors d'une génération de code dite classique (initiée par generate()),
CodeWorker ne prendra pas la liberté de supprimer une zône de code protégée, même si vous avez mal déclaré les symboles
marquant les débuts et fins de commentaires. Nous en apprendrons plus à propos de la déclaration du format des
commentaires après l'exemple qui suit.
Voici ce que devient l'algorithme que nous avions perdu tout à l'heure :
public class voiture extends Jouet {
public String alimentation() { return "piles"; }
public int piles() { return "4"; }
public String typeDePile() { return "LR6"; }
public void jouer() {
//##protect##"corps de la méthode 'jouer()'"
//##protect##"corps de la méthode 'jouer()'"
}
}
$TMP/Developpez.com/org/tutorial/examples/voiture.java
...
public void jouer() {
//##protect##"corps de la méthode 'jouer()'"
do {
tourneAleatoirement(3/*fois*/);
aligneVehicule();
metGaz();
constateSortieDeRoute();
} while (essieuValide());
//##protect##"corps de la méthode 'jouer()'"
}
...
On remarquera que les balises ont adopté le format des commentaires mono-ligne du Java et du C++ pour s'annoncer. Il se
trouve que cela coïncide de même avec le format des commentaires mono-ligne dans CodeWorker : public void jouer() {
//##protect##"corps de la méthode 'jouer()'"
do {
tourneAleatoirement(3/*fois*/);
aligneVehicule();
metGaz();
constateSortieDeRoute();
} while (essieuValide());
//##protect##"corps de la méthode 'jouer()'"
}
...
//
pour commencer
et un retour-chariot pour terminer.
Que faire si vous générez un fichier d'un type qui n'admet pas ce format de commentaire ? Il suffit d'informer l'outil du
format de commentaire souhaité : setCommentBegin() pour spécifier le texte de
début d'un commentaire et setCommentEnd() pour donner le texte de fin d'un
commentaire. Ces informations doit être fournies impérativement avant de lancer la génération de code classique. Dans le cas
contraire, les zônes de codes protégées n'auront pas été détectées pendant la génération et auront donc disparu après.
Voici un tableau récapitulatif des valeurs à transmettre à ces procédures, pour quelques formats de fichier habituels :
| Type de fichier | setCommentBegin | setCommentEnd |
| C++ et Java | "//", valeur par défaut | "\n", valeur par défaut |
| C | "/*" | "*/" |
| Ada | "--" | "\n", valeur par défaut |
| HTML et XML | "<!--" | "-->" |
| LaTeX | "%" | "\n", valeur par défaut |
| Fonction | Description |
| getProtectedArea(cle_unique) | Récupère le contenu de la zône de code protégée associée à la clé. Si la zône de code protégée a déjà été replacée dans le fichier par la procédure setProtectedArea() ou autre, cette fonction retourne une chaîne vide. |
| getProtectedAreaKeys(liste) | Alimente la liste avec le nom de toutes les zônes de code protégées qui avaient été extraites de l'ancienne version du fichier en cours de génération. Les clés et valeurs de la table d'association liste valent le nom des zônes de code protégées, et sont rangées dans l'ordre lexicographique. La fonction retourne le nombre de zônes extraites. |
| populateProtectedArea(cle_unique, contenu) | Assigne un contenu à une zône de code protégée, et place celle-ci dans le fichier en cours de génération. |
| remainingProtectedAreas(liste) | Se comporte comme getProtectedAreaKeys(), à ceci près que seules les zônes de code protégées non encore replacées dans le fichier sont citées. |
| removeProtectedArea(cle_unique) | Supprime une zône de code protégée de celles qu'il reste à replacer. |
| Procédure | Description |
| insertText(position, texte) | Insère du texte à une certaine position dans le fichier en cours de génération. La position compte à partir de 0 (début de fichier). |
| insertTextOnce(position, texte) | Insère du texte uniquement s'il n'a pas déjà été inséré par cette procédure ou par insertTextOnceToFloatingLocation(). |
| insertTextOnceToFloatingLocation(position_flottante, texte) | Insère du texte à une position flottante dans le fichier en cours de génération, à condition qu'il n'ait pas encore été inséré. Une position flottante se présente sous la forme d'une clé à laquelle est attachée une position dans le fichier. Cette position est susceptible de varier pour des raisons qui seront exposées plus loin. |
| insertTextOnceToFloatingLocation(position_flottante, texte) | Insère du texte à une position flottante. |
| overwritePortion(position, texte, recouvrement) | Recouvre une partie déjà générée, à partir d'une position donnée, et insère le reste si la zône à recouvrir est plus courte que le texte. |
Supposons à présent que nous souhaitions introduire un commentaire juste avant la déclaration de notre classe Java, chaque fois qu'une nouvelle garniture se présente :
$TMP/Developpez.com/dessert.java.cwt
package org.tutorial.examples;
/**
* Un dessert proposé par la pâtisserie du quartier
@
local iCommentaire = getOutputLocation();
@ **/
public class @this@ extends Dessert {
public String pate() { return "@this.pate@"; }
@
foreach i in this.garniture {
@ public void etale_@i.key()@() {
@
setProtectedArea(i.key());
@}
@
insertText(iCommentaire, " * Ne pas oublier d'étaler la garniture '" + i.key()
+ "', quantité = " + i + endl());
}
@}
Reprenons le script d'enchaînement utilisé pour générer les jouets et adaptons-le :
/**
* Un dessert proposé par la pâtisserie du quartier
@
local iCommentaire = getOutputLocation();
@ **/
public class @this@ extends Dessert {
public String pate() { return "@this.pate@"; }
@
foreach i in this.garniture {
@ public void etale_@i.key()@() {
@
setProtectedArea(i.key());
@}
@
insertText(iCommentaire, " * Ne pas oublier d'étaler la garniture '" + i.key()
+ "', quantité = " + i + endl());
}
@}
$TMP/Developpez.com/objets.java.cws
codeworker $TMP/Developpez.com/objets.java.cws -nologo
parseAsBNF(getEnv("TMP") + "/Developpez.com/objets.cwp", project,
getEnv("TMP") + "/Developpez.com/objets.txt");
foreach i in project.jouets {
generate(getEnv("TMP") + "/Developpez.com/jouet.java.cwt",
i,
getEnv("TMP") + "/Developpez.com/org/tutorial/examples/" + i.categorie + ".java");
}
foreach i in project.desserts {
generate(getEnv("TMP") + "/Developpez.com/dessert.java.cwt",
i,
getEnv("TMP") + "/Developpez.com/org/tutorial/examples/" + i + ".java");
}
Notons que la fonction getOutputLocation() donne la position courante du curseur
d'écriture dans le fichier à générer.
Nous obtenons la classe Java tartelette :
getEnv("TMP") + "/Developpez.com/objets.txt");
foreach i in project.jouets {
generate(getEnv("TMP") + "/Developpez.com/jouet.java.cwt",
i,
getEnv("TMP") + "/Developpez.com/org/tutorial/examples/" + i.categorie + ".java");
}
foreach i in project.desserts {
generate(getEnv("TMP") + "/Developpez.com/dessert.java.cwt",
i,
getEnv("TMP") + "/Developpez.com/org/tutorial/examples/" + i + ".java");
}
$TMP/Developpez.com/org/tutorial/examples/tartelette.java
package org.tutorial.examples;
/**
* Un dessert proposé par la pâtisserie du quartier
* Ne pas oublier d'étaler la garniture 'abricot', quantité = 0.5
* Ne pas oublier d'étaler la garniture 'fraise', quantité = 8
**/
public class tartelette extends Dessert {
public String pate() { return "sablee"; }
public void etale_fraise() {
//##protect##"fraise"
//##protect##"fraise"
}
public void etale_abricot() {
//##protect##"abricot"
//##protect##"abricot"
}
}
Supposons à présent que nous souhaitions importer la classe java.util.ArrayList quand une garniture à base de
fraise est rencontrée. On obtient alors :
/**
* Un dessert proposé par la pâtisserie du quartier
* Ne pas oublier d'étaler la garniture 'abricot', quantité = 0.5
* Ne pas oublier d'étaler la garniture 'fraise', quantité = 8
**/
public class tartelette extends Dessert {
public String pate() { return "sablee"; }
public void etale_fraise() {
//##protect##"fraise"
//##protect##"fraise"
}
public void etale_abricot() {
//##protect##"abricot"
//##protect##"abricot"
}
}
$TMP/Developpez.com/dessert.java.cwt
codeworker $TMP/Developpez.com/objets.java.cws -nologo
package org.tutorial.examples;
@
local iImports = getOutputLocation();
@
/**
* Un dessert proposé par la pâtisserie du quartier
@
local iCommentaire = getOutputLocation();
@ **/
public class @this@ extends Dessert {
public String pate() { return "@this.pate@"; }
@
foreach i in this.garniture {
@ public void etale_@i.key()@() {
@
setProtectedArea(i.key());
@ }
@
insertText(iCommentaire, " * Ne pas oublier d'étaler la garniture '" + i.key()
+ "', quantité = " + i + endl());
if i.key() == "fraise" {
insertText(iImports, "import java.util.ArrayList;" + endl());
}
}
@}
Le résultat obtenu n'est pas fameux. La première ligne du cartouche de commentaire a été éclatée en deux morceaux,
séparés par le commentaire sur la garniture abricot. Que s'est-il passé ? Nous avions conservé la position
réservée à la garniture dans le cartouche de commentaire. Cependant, l'import de la classe ArrayList fut
inséré devant le cartouche. Du coup, la position du cartouche aurait dû être corrigée de la taille de la ligne d'import.
@
local iImports = getOutputLocation();
@
/**
* Un dessert proposé par la pâtisserie du quartier
@
local iCommentaire = getOutputLocation();
@ **/
public class @this@ extends Dessert {
public String pate() { return "@this.pate@"; }
@
foreach i in this.garniture {
@ public void etale_@i.key()@() {
@
setProtectedArea(i.key());
@ }
@
insertText(iCommentaire, " * Ne pas oublier d'étaler la garniture '" + i.key()
+ "', quantité = " + i + endl());
if i.key() == "fraise" {
insertText(iImports, "import java.util.ArrayList;" + endl());
}
}
@}
$TMP/Developpez.com/org/tutorial/examples/tartelette.java
package org.tutorial.examples;
import java.util.ArrayList;
/**
* Un dessert proposé pa * Ne pas oublier d'étaler la garniture 'abricot', quantité = 0.5
r la pâtisserie du quartier
* Ne pas oublier d'étaler la garniture 'fraise', quantité = 8
**/
public class tartelette extends Dessert {
public String pate() { return "sablee"; }
public void etale_fraise() {
//##protect##"fraise"
//##protect##"fraise"
}
public void etale_abricot() {
//##protect##"abricot"
//##protect##"abricot"
}
}
Pour ne pas souffrir des effets de bord causés par une insertion de texte avant une position conservée, il existe les
positions dites flottantes. Une position flottante consiste en une clé associée à une position dans le
fichier. Cette position variera automatiquement en fonction des insertions qui seront opérées au dessus ou exactement sur
elles. Pour récupérer la position physique (dans le fichier) d'une position flottante, on passe par la fonction
getFloatingLocation(), qui attend une clé. Pour créer ou changer une position
flottante, on passe par la procédure newFloatingLocation().
Corrigeons notre modèle de génération. L'assignation de la position fixe iCommentaire est remplacée par la ligne
newFloatingLocation("commentaire"). De même, l'insertion de texte traditionnelle est remplacée par
insertTextToFloatingLocation("commentaire", texte). Cette dernière écriture est équivalente à
insertText(getFloatingLocation("commentaire"), texte).
import java.util.ArrayList;
/**
* Un dessert proposé pa * Ne pas oublier d'étaler la garniture 'abricot', quantité = 0.5
r la pâtisserie du quartier
* Ne pas oublier d'étaler la garniture 'fraise', quantité = 8
**/
public class tartelette extends Dessert {
public String pate() { return "sablee"; }
public void etale_fraise() {
//##protect##"fraise"
//##protect##"fraise"
}
public void etale_abricot() {
//##protect##"abricot"
//##protect##"abricot"
}
}
$TMP/Developpez.com/dessert.java.cwt
codeworker $TMP/Developpez.com/objets.java.cws -nologo
package org.tutorial.examples;
@
local iImports = getOutputLocation();
@
/**
* Un dessert proposé par la pâtisserie du quartier
@
newFloatingLocation("commentaire");
@ **/
public class @this@ extends Dessert {
public String pate() { return "@this.pate@"; }
@
foreach i in this.garniture {
@ public void etale_@i.key()@() {
@
setProtectedArea(i.key());
@ }
@
insertTextToFloatingLocation("commentaire", " * Ne pas oublier d'étaler la garniture '" + i.key()
+ "', quantité = " + i + endl());
if i.key() == "fraise" {
insertText(iImports, "import java.util.ArrayList;" + endl());
}
}
@}
Le fichier Java est maintenant construit correctement :
@
local iImports = getOutputLocation();
@
/**
* Un dessert proposé par la pâtisserie du quartier
@
newFloatingLocation("commentaire");
@ **/
public class @this@ extends Dessert {
public String pate() { return "@this.pate@"; }
@
foreach i in this.garniture {
@ public void etale_@i.key()@() {
@
setProtectedArea(i.key());
@ }
@
insertTextToFloatingLocation("commentaire", " * Ne pas oublier d'étaler la garniture '" + i.key()
+ "', quantité = " + i + endl());
if i.key() == "fraise" {
insertText(iImports, "import java.util.ArrayList;" + endl());
}
}
@}
$TMP/Developpez.com/org/tutorial/examples/tartelette.java
package org.tutorial.examples;
import java.util.ArrayList;
/**
* Un dessert proposé par la pâtisserie du quartier
* Ne pas oublier d'étaler la garniture 'fraise', quantité = 8
* Ne pas oublier d'étaler la garniture 'abricot', quantité = 0.5
**/
public class tartelette extends Dessert {
public String pate() { return "sablee"; }
public void etale_fraise() {
//##protect##"fraise"
//##protect##"fraise"
}
public void etale_abricot() {
//##protect##"abricot"
//##protect##"abricot"
}
}
L'expansion de code consiste à injecter du code généré à des emplacements bien définis d'un fichier texte. Ces emplacements
sont repérés par des marqueurs. Un marqueur est une sorte de balise placée entre commentaires, et que CodeWorker sait
détecter.
Les commentaires sont conformes à la syntaxe attendue par le format du fichier à générer par expansion. Ainsi, si le
fichier est au format XML, le marqueur sera placée entre les symboles <!-- et -->. Si
le fichier est un source C, le marqueur sera encadré par les symboles /* et */. Par
défaut, les commentaires sont du type C++ / Java mono-ligne : ils commencents par // et finissent par un
retour-chariot.
Voici quelques exemples de marqueurs, pour les différents formats sus-cités :
import java.util.ArrayList;
/**
* Un dessert proposé par la pâtisserie du quartier
* Ne pas oublier d'étaler la garniture 'fraise', quantité = 8
* Ne pas oublier d'étaler la garniture 'abricot', quantité = 0.5
**/
public class tartelette extends Dessert {
public String pate() { return "sablee"; }
public void etale_fraise() {
//##protect##"fraise"
//##protect##"fraise"
}
public void etale_abricot() {
//##protect##"abricot"
//##protect##"abricot"
}
}
- <!--##markup##"Ceci est une clé, pas forcément unique..."-->
- /*##markup##"...elle est consultable par le modèle de génération..."*/
- //##markup##"...grâce à la fonction 'getMarkupKey()'"
$TMP/Developpez.com/objets.html
<html>
<header><title>Description des objets</title></header>
<body>
Documentation en ligne de nos objets.
<p/>
Tous les jouets:<br/>
<!--##markup##"jouets"-->
<p/>
Tous les desserts:<br/>
<!--##markup##"desserts"-->
</body>
</html>
A présent, écrivons le modèle de génération, sensé injecter la description des jouets et des desserts dans leurs marqueurs
respectifs. Avant cela, il est temps de découvrir l'une de ces fameuse fonctions propres à l'expansion : getMarkupKey(). Elle permet
d'interroger le moteur de génération de code sur la clé du marqueur en cours de traitement. Ainsi, le script pourra distinguer
l'emplacement destiné à la description des jouets, de celui destiné aux desserts. Nous avons effectivement pris soin d'affubler
les marqueurs de clés suffisamment expressives.
<header><title>Description des objets</title></header>
<body>
Documentation en ligne de nos objets.
<p/>
Tous les jouets:<br/>
<!--##markup##"jouets"-->
<p/>
Tous les desserts:<br/>
<!--##markup##"desserts"-->
</body>
</html>
$TMP/Developpez.com/objets.html.cwt
@
if getMarkupKey() == "jouets" {
foreach i in this.jouets {
@
<table border="1"><tr><td colspan="2">Jouet <kbd><b>@i.categorie@</b></kbd></td></tr>
<tr><td>alimentation</td><td><i>@i.alimentation@</i></td></tr>
@
if i.alimentation == "piles" {
@ <tr><td>quantite</td><td><i>@i.alimentation.quantite@</i></td></tr>
<tr><td>taille</td><td><i>@i.alimentation.taille@</i></td></tr>
@
}
@ </table>
@
}
} else if getMarkupKey() == "desserts" {
foreach i in this.desserts {
@
<table border="1"><tr><td colspan="2">Dessert <kbd><b>@i@</b></kbd></td></tr>
<tr><td>pate</td><td><i>@i.pate@</i></td></tr>
@
foreach j in i.garniture {
@ <tr><td>garniture <i>@j.key()@</i></td><td><i>@j@</i></td></tr>
@
}
@ </table>
@
}
}
Enrichissons à présent le script d'enchainement utilisé dans la section traitant de la génération classique, par l'ajout
d'une dernière ligne chargée de lancer l'expansion de code. N'oublions pas de spécifier le format des commentaires du HTML.
if getMarkupKey() == "jouets" {
foreach i in this.jouets {
@
<table border="1"><tr><td colspan="2">Jouet <kbd><b>@i.categorie@</b></kbd></td></tr>
<tr><td>alimentation</td><td><i>@i.alimentation@</i></td></tr>
@
if i.alimentation == "piles" {
@ <tr><td>quantite</td><td><i>@i.alimentation.quantite@</i></td></tr>
<tr><td>taille</td><td><i>@i.alimentation.taille@</i></td></tr>
@
}
@ </table>
@
}
} else if getMarkupKey() == "desserts" {
foreach i in this.desserts {
@
<table border="1"><tr><td colspan="2">Dessert <kbd><b>@i@</b></kbd></td></tr>
<tr><td>pate</td><td><i>@i.pate@</i></td></tr>
@
foreach j in i.garniture {
@ <tr><td>garniture <i>@j.key()@</i></td><td><i>@j@</i></td></tr>
@
}
@ </table>
@
}
}
$TMP/Developpez.com/objets.cws
codeworker $TMP/Developpez.com/objets.cws -nologo
parseAsBNF(getEnv("TMP") + "/Developpez.com/objets.cwp", project,
getEnv("TMP") + "/Developpez.com/objets.txt");
foreach i in project.jouets {
generate(getEnv("TMP") + "/Developpez.com/jouet.java.cwt",
i,
getEnv("TMP") + "/Developpez.com/org/tutorial/examples/" + i.categorie + ".java");
}
foreach i in project.desserts {
generate(getEnv("TMP") + "/Developpez.com/dessert.java.cwt",
i,
getEnv("TMP") + "/Developpez.com/org/tutorial/examples/" + i + ".java");
}
setCommentBegin("<!--");
setCommentEnd("-->");
expand(getEnv("TMP") + "/Developpez.com/objets.html.cwt", project,
getEnv("TMP") + "/Developpez.com/objets.html");
Exécutons le script d'enchainement. Notre documentation se voit alors transformée :
getEnv("TMP") + "/Developpez.com/objets.txt");
foreach i in project.jouets {
generate(getEnv("TMP") + "/Developpez.com/jouet.java.cwt",
i,
getEnv("TMP") + "/Developpez.com/org/tutorial/examples/" + i.categorie + ".java");
}
foreach i in project.desserts {
generate(getEnv("TMP") + "/Developpez.com/dessert.java.cwt",
i,
getEnv("TMP") + "/Developpez.com/org/tutorial/examples/" + i + ".java");
}
setCommentBegin("<!--");
setCommentEnd("-->");
expand(getEnv("TMP") + "/Developpez.com/objets.html.cwt", project,
getEnv("TMP") + "/Developpez.com/objets.html");
$TMP/Developpez.com/objets.html
<html>
<header><title>Description des objets</title></header>
<body>
Documentation en ligne de nos objets.
<p/>
Tous les jouets:<br/>
<!--##markup##"jouets"--><!--##begin##"jouets"-->
<table border="1"><tr><td colspan="2">Jouet <kbd><b>voiture</b></kbd></td></tr>
<tr><td>alimentation</td><td><i>piles</i></td></tr>
<tr><td>quantite</td><td><i>4</i></td></tr>
<tr><td>taille</td><td><i>LR6</i></td></tr>
</table>
<!--##end##"jouets"-->
<p/>
Tous les desserts:<br/>
<!--##markup##"desserts"--><!--##begin##"desserts"-->
<table border="1"><tr><td colspan="2">Dessert <kbd><b>tartelette</b></kbd></td></tr>
<tr><td>pate</td><td><i>sablee</i></td></tr>
<tr><td>garniture <i>fraise</i></td><td><i>8</i></td></tr>
<tr><td>garniture <i>abricot</i></td><td><i>0.5</i></td></tr>
</table>
<!--##end##"desserts"-->
</body>
</html>
On constate que le code a été injecté sous les marqueurs. Il est délimité par les balises ##begin##"clé du marqueur"
et ##end##"clé du marqueur". Ces balises permettent le repérage du bloc injecté, sans confusion possible
avec le reste du document. Sans cela, une deuxième expansion du même fichier injecterait le code en doublon sous les marqueurs.
Dans votre butineur favori, la documentation rend ainsi :
<header><title>Description des objets</title></header>
<body>
Documentation en ligne de nos objets.
<p/>
Tous les jouets:<br/>
<!--##markup##"jouets"--><!--##begin##"jouets"-->
<table border="1"><tr><td colspan="2">Jouet <kbd><b>voiture</b></kbd></td></tr>
<tr><td>alimentation</td><td><i>piles</i></td></tr>
<tr><td>quantite</td><td><i>4</i></td></tr>
<tr><td>taille</td><td><i>LR6</i></td></tr>
</table>
<!--##end##"jouets"-->
<p/>
Tous les desserts:<br/>
<!--##markup##"desserts"--><!--##begin##"desserts"-->
<table border="1"><tr><td colspan="2">Dessert <kbd><b>tartelette</b></kbd></td></tr>
<tr><td>pate</td><td><i>sablee</i></td></tr>
<tr><td>garniture <i>fraise</i></td><td><i>8</i></td></tr>
<tr><td>garniture <i>abricot</i></td><td><i>0.5</i></td></tr>
</table>
<!--##end##"desserts"-->
</body>
</html>
 Lorsqu'un modèle d'expansion de code n'a pas lieu d'être réutilisé pour un autre marqueur, parce que seul un marqueur dans
un fichier texte bien spécifique est concerné par ce modèle, alors la possibilité est offerte d'incruster ce script sous
le marqueur.
Le script est encadré par les balises ##script##, placées entre commentaires, dans la même logique que
pour les marqueurs. Le script à proprement parler est placé entre commentaires. En effet, il faut le rendre invisible aux
outils chargés de traiter le fichier source : compilateurs pour Ada ou Java, interpréteurs pour un shell,
butineurs pour HTML... Si le type de commentaire est mono-ligne, chaque ligne du script doit être commentée. S'il est
multi-ligne, l'ensemble du script peut être placé entre commentaire. Il existe une exception pour les langages dont le
commentaire mono-ligne est un // : le commentaire multi-ligne /* ... */ est
automatiquement toléré.
Exemple :
On rajoute l'affichage du nombre d'objets sous la forme d'un script embarqué, et on lance l'exécution :
Lorsqu'un modèle d'expansion de code n'a pas lieu d'être réutilisé pour un autre marqueur, parce que seul un marqueur dans
un fichier texte bien spécifique est concerné par ce modèle, alors la possibilité est offerte d'incruster ce script sous
le marqueur.
Le script est encadré par les balises ##script##, placées entre commentaires, dans la même logique que
pour les marqueurs. Le script à proprement parler est placé entre commentaires. En effet, il faut le rendre invisible aux
outils chargés de traiter le fichier source : compilateurs pour Ada ou Java, interpréteurs pour un shell,
butineurs pour HTML... Si le type de commentaire est mono-ligne, chaque ligne du script doit être commentée. S'il est
multi-ligne, l'ensemble du script peut être placé entre commentaire. Il existe une exception pour les langages dont le
commentaire mono-ligne est un // : le commentaire multi-ligne /* ... */ est
automatiquement toléré.
Exemple :
On rajoute l'affichage du nombre d'objets sous la forme d'un script embarqué, et on lance l'exécution :
$TMP/Developpez.com/objets.html
codeworker $TMP/Developpez.com/objets.cws -nologo
<html>
<header><title>Description des objets</title></header>
<body>
Documentation en ligne de nos objets.<br>
Nombre d'objets :
<!--##markup##"nombre d'objets"--><!--##script##-->
<!--
local iNbObjets = $this.jouets.size() + this.desserts.size()$;
@@iNbObjets@@
-->
<!--##script##-->
<p/>
Tous les jouets:<br/>
<!--##markup##"jouets"-->
<p/>
Tous les desserts:<br/>
<!--##markup##"desserts"-->
</body>
</html>
Voici le résultat obtenu :
<header><title>Description des objets</title></header>
<body>
Documentation en ligne de nos objets.<br>
Nombre d'objets :
<!--##markup##"nombre d'objets"--><!--##script##-->
<!--
local iNbObjets = $this.jouets.size() + this.desserts.size()$;
@@iNbObjets@@
-->
<!--##script##-->
<p/>
Tous les jouets:<br/>
<!--##markup##"jouets"-->
<p/>
Tous les desserts:<br/>
<!--##markup##"desserts"-->
</body>
</html>
$TMP/Developpez.com/objets.html
<html>
<header><title>Description des objets</title></header>
<body>
Documentation en ligne de nos objets.<br>
Nombre d'objets :
<!--##markup##"nombre d'objets"--><!--##script##-->
<!--
local iNbObjets = $this.jouets.size() + this.desserts.size()$;
@@iNbObjets@@
-->
<!--##script##--><!--##begin##"nombre d'objets"-->2<!--##end##"nombre d'objets"-->
<p/>
Tous les jouets:<br/>
<!--##markup##"jouets"--><!--##begin##"jouets"-->
<table border="1"><tr><td colspan="2">Jouet <kbd><b>voiture</b></kbd></td></tr>
<tr><td>alimentation</td><td><i>piles</i></td></tr>
<tr><td>quantite</td><td><i>4</i></td></tr>
<tr><td>taille</td><td><i>LR6</i></td></tr>
</table>
<!--##end##"jouets"-->
<p/>
Tous les desserts:<br/>
<!--##markup##"desserts"--><!--##begin##"desserts"-->
<table border="1"><tr><td colspan="2">Dessert <kbd><b>tartelette</b></kbd></td></tr>
<tr><td>pate</td><td><i>sablee</i></td></tr>
<tr><td>garniture <i>fraise</i></td><td><i>8</i></td></tr>
<tr><td>garniture <i>abricot</i></td><td><i>0.5</i></td></tr>
</table>
<!--##end##"desserts"-->
</body>
</html>
Supposons à présent que nous souhaitions étendre nos sources Java avec des valeurs énumérées qui, pour chaque type
d'énumération, propose une conversion de l'énuméré vers le type String et vice-versa. En Java, les valeurs
énumérées sont représentées par des entiers constants (final int).
Exemple :
<header><title>Description des objets</title></header>
<body>
Documentation en ligne de nos objets.<br>
Nombre d'objets :
<!--##markup##"nombre d'objets"--><!--##script##-->
<!--
local iNbObjets = $this.jouets.size() + this.desserts.size()$;
@@iNbObjets@@
-->
<!--##script##--><!--##begin##"nombre d'objets"-->2<!--##end##"nombre d'objets"-->
<p/>
Tous les jouets:<br/>
<!--##markup##"jouets"--><!--##begin##"jouets"-->
<table border="1"><tr><td colspan="2">Jouet <kbd><b>voiture</b></kbd></td></tr>
<tr><td>alimentation</td><td><i>piles</i></td></tr>
<tr><td>quantite</td><td><i>4</i></td></tr>
<tr><td>taille</td><td><i>LR6</i></td></tr>
</table>
<!--##end##"jouets"-->
<p/>
Tous les desserts:<br/>
<!--##markup##"desserts"--><!--##begin##"desserts"-->
<table border="1"><tr><td colspan="2">Dessert <kbd><b>tartelette</b></kbd></td></tr>
<tr><td>pate</td><td><i>sablee</i></td></tr>
<tr><td>garniture <i>fraise</i></td><td><i>8</i></td></tr>
<tr><td>garniture <i>abricot</i></td><td><i>0.5</i></td></tr>
</table>
<!--##end##"desserts"-->
</body>
</html>
$TMP/Developpez.com/org/tutorial/examples/Dessert.java
package org.tutorial.examples;
public class Dessert {
// énumération de fruits (type d'énumération = 'FRUITS') :
public final int fraise = 1;
public final int abricot = 2;
public final int peche = 3;
public final int banane = 4;
// méthodes de conversion sur 'FRUITS' :
public String FRUITStoString(int iFruit) {
switch(iFruit) {
case 1: return "fraise";
case 2: return "abricot";
case 3: return "peche";
case 4: return "banane";
}
return null;
}
public int stringToFRUITS(String sFruit) {
if (sFruit.equals("fraise")) return 1;
if (sFruit.equals("abricot")) return 2;
if (sFruit.equals("peche")) return 3;
if (sFruit.equals("banane")) return 4;
return -1;
}
}
Maintenant, imaginons que cette énumération soit amenée à grossir, ou qu'il faille décaler la valeur entière attachée
à chaque énuméré. Il ne faudra jamais oublier de répercuter ces changements dans les méthodes de conversion. Imaginons
à présent que nous souhaitions appliquer exactement le même modèle de conception sur d'autres type énumérés : la liste des
sommets de plus de 8000m, toutes les pierres précieuses taillées à Anvers, ... Voilà bien du code répétitif et rébarbatif
qu'il faudra maintenir.
Une solution toute simple est d'introduire un marqueur à l'emplacement des descriptions d'énumérations, d'y attacher la
liste des énumérés et de leurs valeurs entières, puis de lancer un modèle d'expansion de code qui génèrera pour nous tout
ce code fastidieux.
Pour attacher de l'information utile localement à un marqueur, on utilise les balises ##data##. Ces balises
délimitent le champ des données, qui reste totalement libres. Pour les mêmes raisons que l'embarcation de script, les
données sont placées entre commentaires. On récupère les données rattachées au marqueur à l'aide de la fonction
getMarkupValue(). Les commentaires ne sont pas retirés du bloc de données retourné.
Reprenons notre exemple :
public class Dessert {
// énumération de fruits (type d'énumération = 'FRUITS') :
public final int fraise = 1;
public final int abricot = 2;
public final int peche = 3;
public final int banane = 4;
// méthodes de conversion sur 'FRUITS' :
public String FRUITStoString(int iFruit) {
switch(iFruit) {
case 1: return "fraise";
case 2: return "abricot";
case 3: return "peche";
case 4: return "banane";
}
return null;
}
public int stringToFRUITS(String sFruit) {
if (sFruit.equals("fraise")) return 1;
if (sFruit.equals("abricot")) return 2;
if (sFruit.equals("peche")) return 3;
if (sFruit.equals("banane")) return 4;
return -1;
}
}
$TMP/Developpez.com/org/tutorial/examples/Dessert.java
package org.tutorial.examples;
public class Dessert {
//##markup##"enum(FRUITS)"
//##data##
//fraise = 1
//abricot = 2
//peche = 3
//banane = 4
//##data##
}
Cela se limite à l'essentiel. Ne reste plus qu'à capitaliser le bout de code appliqué sur l'exemple précédent, pour le
réutiliser sur n'importe quel type énuméré :
public class Dessert {
//##markup##"enum(FRUITS)"
//##data##
//fraise = 1
//abricot = 2
//peche = 3
//banane = 4
//##data##
}
$TMP/Developpez.com/enum.cwt
codeworker -expand $TMP/Developpez.com/enum.cwt $TMP/Developpez.com/org/tutorial/examples/Dessert.java -nologo
@
if startString(getMarkupKey(), "enum(") {
// ce marqueur nous intéresse : il décrit un type énuméré
local sTypeEnumere = coreString(getMarkupKey(), 5, 1);
// parse les données pour alimenter une table d'association avec les énumérés :
// la clé sera le nom de l'énuméré, et la valeur associée sera la constante entière
local enumeres;
parseStringAsBNF({
enumeres ::=
#continue
[
"//"
#continue
whitespaces
#readIdentifier:sEnum
whitespaces '=' whitespaces
#readInteger:sValue
whitespaces ['\r']? '\n'
=> insert this[sEnum] = sValue;
]*
#empty
;
whitespaces ::= [' ' | '\t']*;
}, enumeres, getMarkupValue());
// déclaration des valeurs énumérées
foreach i in enumeres {
@ public static final int @i.key()@ = @i@;
@
}
// enum to String
@
public static String @sTypeEnumere@toString(int i@sTypeEnumere@) {
switch(i@sTypeEnumere@) {
@
foreach i in enumeres {
@ case @i@: return "@i.key()@";
@
}
@ }
return null;
}
@
// String to enum
@
public static int stringTo@sTypeEnumere@(String s@sTypeEnumere@) {
@
foreach i in enumeres {
@ if (s@sTypeEnumere@.equals("@i.key()@")) return @i@;
@
}
@ return -1;
}
@
}
Et voici à présent l'aspect que prend notre classe Java :
if startString(getMarkupKey(), "enum(") {
// ce marqueur nous intéresse : il décrit un type énuméré
local sTypeEnumere = coreString(getMarkupKey(), 5, 1);
// parse les données pour alimenter une table d'association avec les énumérés :
// la clé sera le nom de l'énuméré, et la valeur associée sera la constante entière
local enumeres;
parseStringAsBNF({
enumeres ::=
#continue
[
"//"
#continue
whitespaces
#readIdentifier:sEnum
whitespaces '=' whitespaces
#readInteger:sValue
whitespaces ['\r']? '\n'
=> insert this[sEnum] = sValue;
]*
#empty
;
whitespaces ::= [' ' | '\t']*;
}, enumeres, getMarkupValue());
// déclaration des valeurs énumérées
foreach i in enumeres {
@ public static final int @i.key()@ = @i@;
@
}
// enum to String
@
public static String @sTypeEnumere@toString(int i@sTypeEnumere@) {
switch(i@sTypeEnumere@) {
@
foreach i in enumeres {
@ case @i@: return "@i.key()@";
@
}
@ }
return null;
}
@
// String to enum
@
public static int stringTo@sTypeEnumere@(String s@sTypeEnumere@) {
@
foreach i in enumeres {
@ if (s@sTypeEnumere@.equals("@i.key()@")) return @i@;
@
}
@ return -1;
}
@
}
$TMP/Developpez.com/org/tutorial/examples/Dessert.java
package org.tutorial.examples;
public class Dessert {
//##markup##"enum(FRUITS)"
//##data##
//fraise = 1
//abricot = 2
//peche = 3
//banane = 4
//##data##
//##begin##"enum(FRUITS)"
public static final int fraise = 1;
public static final int abricot = 2;
public static final int peche = 3;
public static final int banane = 4;
public static String FRUITStoString(int iFRUITS) {
switch(iFRUITS) {
case 1: return "fraise";
case 2: return "abricot";
case 3: return "peche";
case 4: return "banane";
}
return null;
}
public static int stringToFRUITS(String sFRUITS) {
if (sFRUITS.equals("fraise")) return 1;
if (sFRUITS.equals("abricot")) return 2;
if (sFRUITS.equals("peche")) return 3;
if (sFRUITS.equals("banane")) return 4;
return -1;
}
//##end##"enum(FRUITS)"
}
Reprenons notre exemple d'application sur le videostore, exposé à la fin du chapitre consacré à
l'analyse syntaxique.
Nous allons dessiner un diagramme de classes à partir de notre description IDL "videostore.idl", en
utilisant un gratuiciel nommé GraphViz et développé par
ATT. Ce logiciel permet de dessiner une grande variété de graphes, dont certains peuvent ressembler à des diagrammes
de classe. Il prend en entrée la description du graphe à produire, et sort ce dernier dans un format d'image reconnu
(PNG notamment). On commence par décrire les noeuds du graphe (les classes de notre diagramme) et on poursuit en
présentant les relations entre les noeuds (associations entre classes). Il n'est pas nécessaire de connaître la syntaxe
du langage de description pour comprendre la suite.
Voici le modèle de génération chargé de composer la description du diagramme de classes pour GraphViz :
public class Dessert {
//##markup##"enum(FRUITS)"
//##data##
//fraise = 1
//abricot = 2
//peche = 3
//banane = 4
//##data##
//##begin##"enum(FRUITS)"
public static final int fraise = 1;
public static final int abricot = 2;
public static final int peche = 3;
public static final int banane = 4;
public static String FRUITStoString(int iFRUITS) {
switch(iFRUITS) {
case 1: return "fraise";
case 2: return "abricot";
case 3: return "peche";
case 4: return "banane";
}
return null;
}
public static int stringToFRUITS(String sFRUITS) {
if (sFRUITS.equals("fraise")) return 1;
if (sFRUITS.equals("abricot")) return 2;
if (sFRUITS.equals("peche")) return 3;
if (sFRUITS.equals("banane")) return 4;
return -1;
}
//##end##"enum(FRUITS)"
}
$TMP/Developpez.com/videostore-graphviz.cwt
@
// on réclame un graphe où les noeuds sont des boîtes concaténées,
// avec un fond et entourées de rouge ;
// en fait, une classe contatène un boite pour le nom avec une autre pour
// les attributs et une dernière pour les méthodes
@digraph structs {
node [shape=record,style=filled,color=red3];
@
// Fonction utilitaire qui vérifie si un attribut est une association on non.
// Une association est une relation entre deux classes, autre que l'héritage,
// où au moins l'une des deux conserve une référence sur l'autre.
// Ici, les associations concernent les attributs dont le type est une classe
// ou une séquence de classes.
// Paramètre :
// - le type de l'attribut
function estUneAssociation(theType : node) {
if theType.is_sequence {
return theType.element.estUneAssociation();
}
return theType.is_interface || theType.is_structure;
}
// ----------------------
// Génération des classes
// ----------------------
// Cette fonction retourne le type d'un attribut, tel qu'il doit s'afficher
// dans une classe
function serialiseType(myType : node) {
if myType.is_sequence return serialiseType(myType.element) + "[]";
return myType;
}
// Génèration d'une classe sous la forme d'un rectangle décomposé en trois
// sections : le nom, les attributs et les méthodes.
// On considère que les interfaces et les structures sont des classes.
function genereClasse(classe : node) {
@ @classe.name@ [shape=record,label="{@classe.name@|{@
local bAtLeastOne = false;
// on parcourt tous les attributs, pour les afficher sous le nom
foreach i in classe.attributes {
if !i.type.estUneAssociation() {
// c'est bien un attribut à prendre en compte,
// et non pas une association
if !bAtLeastOne {
bAtLeastOne = true;
} else {
@\n@
}
@@i.name@\ :\ @serialiseType(i.type)@@
}
}
if !bAtLeastOne {
// s'il n'y a pas d'attributs, on glisse une ligne vide dans la
// section consacrée aux attributs
@\n@
}
// on ouvre une nouvelle section, pour les méthodes
@}|{@
if !classe.methods.empty() {
// on affiche les méthodes au format
// <nom>(<param> : <mode> <type>, ...)
// ou
// <nom>(<param> : <mode> <type>, ...) : <type_retour>
foreach i in classe.methods {
@@i.name@(@
foreach j in i.parameters {
if !j.first() {
@, @
}
@@j.name@:@j.mode@ @j.type.serialiseType()@@
}
@)@
if i.returnType.existVariable() {
@ : @serialiseType(i.type)@\n@
} else {
@\n@
}
}
} else {
// s'il n'y a pas de méthodes, on glisse une ligne vide dans la
// section consacrée aux méthodes
@\n@
}
@}}",fillcolor=yellow,];
@
}
foreach i in this.interfaces {
genereClasse(i);
}
foreach i in this.structures {
genereClasse(i);
}
@
@
// ---------------------------
// Génération des associations
// ---------------------------
// Génération de toutes les associations entre classes, ainsi que du lien d'héritage.
function genereAssociation(classe : node) {
if existVariable(classe.inheritance) {
// le lien d'héritage termine par une grosse flêche, comme en UML
@ @classe.name@ -> @classe.inheritance@ [arrowhead=empty,arrowsize=2.0];
@
}
foreach i in classe.attributes {
if i.type.estUneAssociation() {
// on ne prend en compte que les associations (attributs qui pointent
// vers d'autres objets)
localref myType = i.type;
if myType.is_sequence {
// si c'est une séquence, on récupère le type de l'élément
ref myType = myType.element;
}
// on établit une relation vers la classe destination
@ @classe.name@ -> @myType@ [@
// on construit le rôle de l'association : nom du lien et
// arité
local sRole = i.name;
if i.type.is_sequence {
set sRole = "[0..*] " + sRole;
} else {
set sRole = "[0..1] " + sRole;
}
// le rôle est placé à l'extrémité de la flêche qui relie la classe
// à l'objet
@arrowhead=normal,arrowsize=1.0,headlabel="@sRole@"];
@
}
}
}
foreach i in this.interfaces {
genereAssociation(i);
}
foreach i in this.structures {
genereAssociation(i);
}
@}
Ecrivons un script d'enchaînement, dont le rôle sera d'extraire l'information utile du fichier IDL et de
produire le diagramme de classe :
// on réclame un graphe où les noeuds sont des boîtes concaténées,
// avec un fond et entourées de rouge ;
// en fait, une classe contatène un boite pour le nom avec une autre pour
// les attributs et une dernière pour les méthodes
@digraph structs {
node [shape=record,style=filled,color=red3];
@
// Fonction utilitaire qui vérifie si un attribut est une association on non.
// Une association est une relation entre deux classes, autre que l'héritage,
// où au moins l'une des deux conserve une référence sur l'autre.
// Ici, les associations concernent les attributs dont le type est une classe
// ou une séquence de classes.
// Paramètre :
// - le type de l'attribut
function estUneAssociation(theType : node) {
if theType.is_sequence {
return theType.element.estUneAssociation();
}
return theType.is_interface || theType.is_structure;
}
// ----------------------
// Génération des classes
// ----------------------
// Cette fonction retourne le type d'un attribut, tel qu'il doit s'afficher
// dans une classe
function serialiseType(myType : node) {
if myType.is_sequence return serialiseType(myType.element) + "[]";
return myType;
}
// Génèration d'une classe sous la forme d'un rectangle décomposé en trois
// sections : le nom, les attributs et les méthodes.
// On considère que les interfaces et les structures sont des classes.
function genereClasse(classe : node) {
@ @classe.name@ [shape=record,label="{@classe.name@|{@
local bAtLeastOne = false;
// on parcourt tous les attributs, pour les afficher sous le nom
foreach i in classe.attributes {
if !i.type.estUneAssociation() {
// c'est bien un attribut à prendre en compte,
// et non pas une association
if !bAtLeastOne {
bAtLeastOne = true;
} else {
@\n@
}
@@i.name@\ :\ @serialiseType(i.type)@@
}
}
if !bAtLeastOne {
// s'il n'y a pas d'attributs, on glisse une ligne vide dans la
// section consacrée aux attributs
@\n@
}
// on ouvre une nouvelle section, pour les méthodes
@}|{@
if !classe.methods.empty() {
// on affiche les méthodes au format
// <nom>(<param> : <mode> <type>, ...)
// ou
// <nom>(<param> : <mode> <type>, ...) : <type_retour>
foreach i in classe.methods {
@@i.name@(@
foreach j in i.parameters {
if !j.first() {
@, @
}
@@j.name@:@j.mode@ @j.type.serialiseType()@@
}
@)@
if i.returnType.existVariable() {
@ : @serialiseType(i.type)@\n@
} else {
@\n@
}
}
} else {
// s'il n'y a pas de méthodes, on glisse une ligne vide dans la
// section consacrée aux méthodes
@\n@
}
@}}",fillcolor=yellow,];
@
}
foreach i in this.interfaces {
genereClasse(i);
}
foreach i in this.structures {
genereClasse(i);
}
@
@
// ---------------------------
// Génération des associations
// ---------------------------
// Génération de toutes les associations entre classes, ainsi que du lien d'héritage.
function genereAssociation(classe : node) {
if existVariable(classe.inheritance) {
// le lien d'héritage termine par une grosse flêche, comme en UML
@ @classe.name@ -> @classe.inheritance@ [arrowhead=empty,arrowsize=2.0];
@
}
foreach i in classe.attributes {
if i.type.estUneAssociation() {
// on ne prend en compte que les associations (attributs qui pointent
// vers d'autres objets)
localref myType = i.type;
if myType.is_sequence {
// si c'est une séquence, on récupère le type de l'élément
ref myType = myType.element;
}
// on établit une relation vers la classe destination
@ @classe.name@ -> @myType@ [@
// on construit le rôle de l'association : nom du lien et
// arité
local sRole = i.name;
if i.type.is_sequence {
set sRole = "[0..*] " + sRole;
} else {
set sRole = "[0..1] " + sRole;
}
// le rôle est placé à l'extrémité de la flêche qui relie la classe
// à l'objet
@arrowhead=normal,arrowsize=1.0,headlabel="@sRole@"];
@
}
}
}
foreach i in this.interfaces {
genereAssociation(i);
}
foreach i in this.structures {
genereAssociation(i);
}
@}
$TMP/Developpez.com/videostore-graphviz.cws
codeworker $TMP/Developpez.com/videostore-graphviz.cws -nologo
parseAsBNF("videostore-parser.cwp", project, getEnv("TMP") + "/Developpez.com/videostore.idl");
generate(getEnv("TMP") + "/Developpez.com/videostore-graphviz.cwt",
project, getEnv("TMP") + "/Developpez.com/videostore.gvz");
// construction du diagramme de classe par GraphViz, dans une image en PNG
// Note : le chemin a été indiqué en dur, pour une plateforme Windows
system("\"c:\\Program Files\\ATT\\GraphViz\\bin\\dot.exe\" -Tpng -o videostoreDiagram.png " +
getEnv("TMP") + "/Developpez.com/videostore.gvz");
Voici le fichier produit pour GraphViz, sur la base de "videostore.idl" :
generate(getEnv("TMP") + "/Developpez.com/videostore-graphviz.cwt",
project, getEnv("TMP") + "/Developpez.com/videostore.gvz");
// construction du diagramme de classe par GraphViz, dans une image en PNG
// Note : le chemin a été indiqué en dur, pour une plateforme Windows
system("\"c:\\Program Files\\ATT\\GraphViz\\bin\\dot.exe\" -Tpng -o videostoreDiagram.png " +
getEnv("TMP") + "/Developpez.com/videostore.gvz");
$TMP/Developpez.com/videostore.gvz
digraph structs {
node [shape=record,style=filled,color=red3];
Produit [shape=record,label="{Produit|{Prix\ :\ double}|{\n}}",fillcolor=yellow,];
Figurine [shape=record,label="{Figurine|{Nom\ :\ string\nPoids\ :\ double}|{\n}}",fillcolor=yellow,
];
DVD [shape=record,label="{DVD|{DestineLocation\ :\ boolean}|{\n}}",fillcolor=yellow,];
HomeCinema [shape=record,label="{HomeCinema|{DestineLocation\ :\ double}|{\n}}",fillcolor=yellow,];
Magasin [shape=record,label="{Magasin|{Nom\ :\ string\nAdresse\ :\ string}|{\n}}",fillcolor=yellow,
];
Videostore [shape=record,label="{Videostore|{\n}|{loue(client:in Client, produit:in Produit, dureeH
oraire:in long)\nachete(client:in Client, produit:in Produit, Quantite:in long)\n}}",fillcolor=yello
w,];
SynopsisFilm [shape=record,label="{SynopsisFilm|{Titre\ :\ string\nMetteurEnScene\ :\ string\nActeu
rs\ :\ string[]\nDureeEnMinutes\ :\ long}|{\n}}",fillcolor=yellow,];
Client [shape=record,label="{Client|{Nom\ :\ string\nAdresse\ :\ string\nCarte\ :\ string}|{\n}}",f
illcolor=yellow,];
BonDeLocation [shape=record,label="{BonDeLocation|{DateRetour\ :\ string\nPrix\ :\ double}|{\n}}",f
illcolor=yellow,];
Figurine -> Produit [arrowhead=empty,arrowsize=2.0];
DVD -> Produit [arrowhead=empty,arrowsize=2.0];
DVD -> SynopsisFilm [arrowhead=normal,arrowsize=1.0,headlabel="[0..1] Synopsis"];
HomeCinema -> Produit [arrowhead=empty,arrowsize=2.0];
Magasin -> Client [arrowhead=normal,arrowsize=1.0,headlabel="[0..*] Clients"];
Magasin -> Produit [arrowhead=normal,arrowsize=1.0,headlabel="[0..*] Produits"];
Videostore -> Magasin [arrowhead=empty,arrowsize=2.0];
Videostore -> BonDeLocation [arrowhead=normal,arrowsize=1.0,headlabel="[0..*] StockSorti"];
BonDeLocation -> Client [arrowhead=normal,arrowsize=1.0,headlabel="[0..1] Client"];
BonDeLocation -> Produit [arrowhead=normal,arrowsize=1.0,headlabel="[0..1] Produit"];
}
GraphViz a construit le diagramme de classes suivant :
node [shape=record,style=filled,color=red3];
Produit [shape=record,label="{Produit|{Prix\ :\ double}|{\n}}",fillcolor=yellow,];
Figurine [shape=record,label="{Figurine|{Nom\ :\ string\nPoids\ :\ double}|{\n}}",fillcolor=yellow,
];
DVD [shape=record,label="{DVD|{DestineLocation\ :\ boolean}|{\n}}",fillcolor=yellow,];
HomeCinema [shape=record,label="{HomeCinema|{DestineLocation\ :\ double}|{\n}}",fillcolor=yellow,];
Magasin [shape=record,label="{Magasin|{Nom\ :\ string\nAdresse\ :\ string}|{\n}}",fillcolor=yellow,
];
Videostore [shape=record,label="{Videostore|{\n}|{loue(client:in Client, produit:in Produit, dureeH
oraire:in long)\nachete(client:in Client, produit:in Produit, Quantite:in long)\n}}",fillcolor=yello
w,];
SynopsisFilm [shape=record,label="{SynopsisFilm|{Titre\ :\ string\nMetteurEnScene\ :\ string\nActeu
rs\ :\ string[]\nDureeEnMinutes\ :\ long}|{\n}}",fillcolor=yellow,];
Client [shape=record,label="{Client|{Nom\ :\ string\nAdresse\ :\ string\nCarte\ :\ string}|{\n}}",f
illcolor=yellow,];
BonDeLocation [shape=record,label="{BonDeLocation|{DateRetour\ :\ string\nPrix\ :\ double}|{\n}}",f
illcolor=yellow,];
Figurine -> Produit [arrowhead=empty,arrowsize=2.0];
DVD -> Produit [arrowhead=empty,arrowsize=2.0];
DVD -> SynopsisFilm [arrowhead=normal,arrowsize=1.0,headlabel="[0..1] Synopsis"];
HomeCinema -> Produit [arrowhead=empty,arrowsize=2.0];
Magasin -> Client [arrowhead=normal,arrowsize=1.0,headlabel="[0..*] Clients"];
Magasin -> Produit [arrowhead=normal,arrowsize=1.0,headlabel="[0..*] Produits"];
Videostore -> Magasin [arrowhead=empty,arrowsize=2.0];
Videostore -> BonDeLocation [arrowhead=normal,arrowsize=1.0,headlabel="[0..*] StockSorti"];
BonDeLocation -> Client [arrowhead=normal,arrowsize=1.0,headlabel="[0..1] Client"];
BonDeLocation -> Produit [arrowhead=normal,arrowsize=1.0,headlabel="[0..1] Produit"];
}
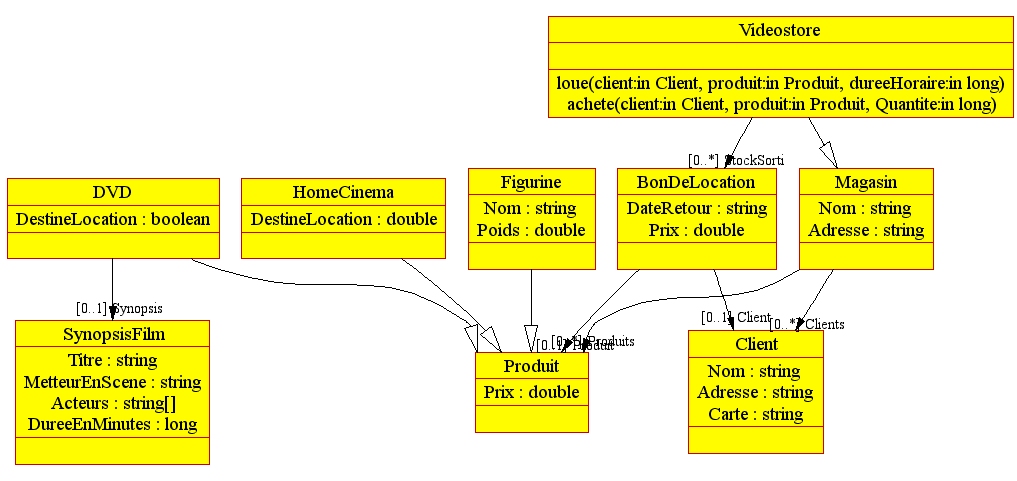 Ce diagramme n'est pas parfait, mais il permet de disposer d'une représentation visuelle rapide de l'information
utile extraite du fichier IDL. Il est fort possible que ce diagramme puisse être amélioré.
Ce chapitre traitera à la fois de la transformation de programmes et de la conversion d'un format vers un autre. Les deux
ont pour point commun que la génèration s'opère au fil de l'analyse syntaxique. Ici, nul besoin a priori de construire un
arbre de parsing. Peut-être juste, de temps à autre, faudra-t-il extraire un peu d'information contextuelle qui s'avérera
exploitable plus loin au cours de l'analyse syntaxique ou de la génération.
Un script de traduction (la transformation est vue comme une traduction sur soi-même) se présente comme un script BNF, à
ceci près que les portions de script standard, introduites par le symbole =>,
autorisent la présence de modèles de génération de code.
La conversion de code consiste à convertir un fichier (ou la partie jugée intéressante du fichier) dans une autre syntaxe.
Reprenons notre fichier de description d'objets jouet et dessert,
et opérons une conversion de ce fichier en HTML, sans passer par une étape séparée d'analyse syntaxique :
Ce diagramme n'est pas parfait, mais il permet de disposer d'une représentation visuelle rapide de l'information
utile extraite du fichier IDL. Il est fort possible que ce diagramme puisse être amélioré.
Ce chapitre traitera à la fois de la transformation de programmes et de la conversion d'un format vers un autre. Les deux
ont pour point commun que la génèration s'opère au fil de l'analyse syntaxique. Ici, nul besoin a priori de construire un
arbre de parsing. Peut-être juste, de temps à autre, faudra-t-il extraire un peu d'information contextuelle qui s'avérera
exploitable plus loin au cours de l'analyse syntaxique ou de la génération.
Un script de traduction (la transformation est vue comme une traduction sur soi-même) se présente comme un script BNF, à
ceci près que les portions de script standard, introduites par le symbole =>,
autorisent la présence de modèles de génération de code.
La conversion de code consiste à convertir un fichier (ou la partie jugée intéressante du fichier) dans une autre syntaxe.
Reprenons notre fichier de description d'objets jouet et dessert,
et opérons une conversion de ce fichier en HTML, sans passer par une étape séparée d'analyse syntaxique :
$TMP/Developpez.com/objets2html.cwp
codeworker -translate $TMP/Developpez.com/objets2html.cwp $TMP/Developpez.com/objets.txt $TMP/Developpez.com/objets.html -nologo
// comme en C ou C++, le '#include' est une directive du préprocesseur
// chargée d'inclure le contenu d'un script en remplacement de la
// directive. Cette directive est acceptée dans les scripts CodeWorker,
// quels que soient leur nature (BNF, modèle de génération, ...)
#include "objets-scanner.cwp"
// on surcharge la règle de tête issue de "objets-scanner.cwp" en débutant sa
// nouvelle définition par le mot-clé '#overload'
#overload objets ::=
// génération de l'entête du fichier HTML
=> {
@<html><header><title>Description des objets</title></header><body>@
}
// on appelle la règle de tête telle que définie dans "objets-scanner.cwp",
// en plaçant '#super::' devant le symbole non-terminal de la règle de tête
#super::objets
// génération de la fin du fichier HTML
=> {
@</body></html>@
}
;
// on redéfinit la lecture d'un jouet pour ajouter la génération de quelques lignes
// de code HTML
#overload objet<"jouet"> ::=
#continue
=> {
@<table border="1"><tr><td colspan="2"><b><i>Jouet</i></b></td></tr>
@
}
[
#readIdentifier:sAttribut
// on affiche le nom de l'attribut ;
// si ce n'est pas un attribut, le symbole non-terminal
// 'jouet_attribut<sAttribut>' échouera, ainsi que tout
// ce bloc entre crochets, MAIS le moteur de traduction
// ne supprimera pas tout ce qui aura été écrit dans
// le fichier cible!
// Le seul moyen d'y parvenir est d'utiliser la directive
// '#implicitCopy' suivie de '#explicitCopy'. Nous verrons
// plus loin ce que cela signifie.
#implicitCopy
#explicitCopy
=> {
@<tr><td><b>@sAttribut@</b></td><td>@
}
jouet_attribut<sAttribut>
=> {
@</td></tr>
@
}
]+
=> {
@</table>
@
}
;
// on redéfinit la lecture de l'attribut 'categorie', pour le retranscrire en HTML
#overload jouet_attribut<"categorie"> ::=
#continue
#readCString:sValue
=> {
// la fonction 'composeHTMLLikeString()' convertit les caractères spéciaux
// en entités HTML
@<i>@sValue.composeHTMLLikeString()@</i>@
}
;
//-----------------------------------------------------------------------------
// A partir de là, vous n'apprendrez rien de nouveau : on applique aux desserts
// le même type de transformations que celles déjà vues sur les jouets
// ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
//-----------------------------------------------------------------------------
Quelle est cette bizarrerie relevée dans la règle de production objet<"jouet">, consistant à introduire
la séquence #implicitCopy #explicitCopy pour signifier d'éliminer du fichier cible tout
ce qui aura été écrit depuis, en cas d'échec du reste de la séquence ?
Il se trouve que le processus d'écriture dans le fichier cible est indépendant du bon aboutissement ou non de la
lecture des portions de texte. Cela signifie que si vous imposez l'écriture de texte au beau milieu d'une séquence BNF
qui échouera plus loin, le texte est conservé dans le fichier cible. Il y a un cas cependant où l'échec d'une séquence
BNF remettra automatiquement en état le fichier cible : la recopie implicite du texte parcouru par l'analyseur
syntaxique dans le fichier cible. Cette fonctionnalité est intensément exploitée par la transformation de programmes,
comme nous le verrons dans le chapitre correspondant.
Ainsi, #implicitCopy ordonne la recopie implicite de la lecture vers le fichier cible. En
cas d'échec dans la suite de la séquence, il remet en l'état le fichier de sortie. Nous ne désirons cependant pas
recopier implicitement le texte lu dans le fichier cible. C'est pourquoi, on rebascule tout de suite en recopie explicite,
qui est le mode habituel, avec la directive #explicitCopy.
// chargée d'inclure le contenu d'un script en remplacement de la
// directive. Cette directive est acceptée dans les scripts CodeWorker,
// quels que soient leur nature (BNF, modèle de génération, ...)
#include "objets-scanner.cwp"
// on surcharge la règle de tête issue de "objets-scanner.cwp" en débutant sa
// nouvelle définition par le mot-clé '#overload'
#overload objets ::=
// génération de l'entête du fichier HTML
=> {
@<html><header><title>Description des objets</title></header><body>@
}
// on appelle la règle de tête telle que définie dans "objets-scanner.cwp",
// en plaçant '#super::' devant le symbole non-terminal de la règle de tête
#super::objets
// génération de la fin du fichier HTML
=> {
@</body></html>@
}
;
// on redéfinit la lecture d'un jouet pour ajouter la génération de quelques lignes
// de code HTML
#overload objet<"jouet"> ::=
#continue
=> {
@<table border="1"><tr><td colspan="2"><b><i>Jouet</i></b></td></tr>
@
}
[
#readIdentifier:sAttribut
// on affiche le nom de l'attribut ;
// si ce n'est pas un attribut, le symbole non-terminal
// 'jouet_attribut<sAttribut>' échouera, ainsi que tout
// ce bloc entre crochets, MAIS le moteur de traduction
// ne supprimera pas tout ce qui aura été écrit dans
// le fichier cible!
// Le seul moyen d'y parvenir est d'utiliser la directive
// '#implicitCopy' suivie de '#explicitCopy'. Nous verrons
// plus loin ce que cela signifie.
#implicitCopy
#explicitCopy
=> {
@<tr><td><b>@sAttribut@</b></td><td>@
}
jouet_attribut<sAttribut>
=> {
@</td></tr>
@
}
]+
=> {
@</table>
@
}
;
// on redéfinit la lecture de l'attribut 'categorie', pour le retranscrire en HTML
#overload jouet_attribut<"categorie"> ::=
#continue
#readCString:sValue
=> {
// la fonction 'composeHTMLLikeString()' convertit les caractères spéciaux
// en entités HTML
@<i>@sValue.composeHTMLLikeString()@</i>@
}
;
//-----------------------------------------------------------------------------
// A partir de là, vous n'apprendrez rien de nouveau : on applique aux desserts
// le même type de transformations que celles déjà vues sur les jouets
// ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
//-----------------------------------------------------------------------------
| #overload et #super::<non-terminal> |
| Passons à présent à la surcharge des règles de production. Nous avons découvert que l'on peut redéfinir une règle de
production à l'aide de la directive de qualification #overload. La nouvelle règle
n'écrase pas l'ancienne, dont le symbole non-terminal reste accessible en employant la directive #super. Le choix
du mot-clé vient du parallèle fait avec Java, où l'exécution d'une méthode implantée dans la classe mère se spécifie
à l'aide du mot-clé super.
Exemple :
// identifiant comme en C ou C++
identifier ::= ['A'..'Z' | 'a'..'z' | '_'] ['A'..'Z' | 'a'..'z' | '_' | '0'..'9']*; // identifiant Java : le '$' en plus ; // on choisit de redéfinir l'identifiant avec '#overload' #overload identifier ::= ['A'..'Z' | 'a'..'z' | '_' | '$'] ['A'..'Z' | 'a'..'z' | '_' | '$' | '0'..'9']* ; // signature d'une fonction élémentaire Java signature_procedure<"Java"> ::= #readIdentifier:"void" identifier '(' ')'; // signature d'une fonction élémentaire C ; // on accède à la règle de production mère de l'identifiant en préfixant // le symbole non-terminal 'identifier' par '#super::' signature_procedure<"C"> ::= #readIdentifier:"void" #super::identifier '(' ')'; |
$TMP/Developpez.com/trace-injector.cwp
codeworker -translate $TMP/Developpez.com/trace-injector.cwp $TMP/Developpez.com/org/tutorial/examples/voiture.java $TMP/Developpez.com/org/tutorial/examples/voiture.java -nologo
transformation ::=
// recopie implicite
#implicitCopy
// on ignore les commentaires Java (les mêmes qu'en C++)
#ignore(C++)
=> local sClassName;
// recherche du nom de la classe, utile pour la trace console
->[
#readIdentifier:"class"
#readIdentifier:sClassName
]
// parcours de toutes les méthodes sans type de retour, et
// injection du code de la trace, si pas déjà présente
[
->[
#readIdentifier:"void"
#readIdentifier:sMethod
// on prévient l'opérateur de saut que si l'on échoue à cette tentative,
// il faudra tenter à nouveau à partir du caractère suivant l'identifiant
// plutôt que d'avancer d'un seul caractère
#nextStep
'(' ->')'
'{'
[
// si l'on a déjà traité cette méthode lors d'une transformation
// précédente, inutile d'y revenir
"System.out.println(\"IN " sClassName "::"
|
=> {
// dès le début de la méthode, on place un message d'entrée,
// et le reste est mis dans un 'try ... finally' de manière
// à afficher le message de sortie dans tous les cas
@
System.out.println("IN @sClassName@::@sMethod@");
try {@
}
// on saute à la fin de la méthode, devant l'accolade fermante du corps
read_brackets
=> {
// à la fin de la méthode, on injecte la trace de sortie
@
} finally {
System.out.println("OUT @sClassName@::@sMethod@");
}
@
}
]
]
]*
->#empty
;
// lire des accolades, éventuellement imbriquées
read_brackets ::=
[
// accolade imbriquée
'{' #continue read_bracket '}'
|
// il ne faut pas se laisser abuser par les accolades contenues
// dans une constante chaîne de caractères ou caractère seul :
// on les ignore pour éviter toute ambiguïté
[#readCChar | #readCString]
|
// on s'arrête lorsqu'on a atteint la fin du fichier source
// ou que l'on est tombé sur une accolade fermante...
// sinon on avance d'un caractère
~['}' | #empty]
]*
;
// recopie implicite
#implicitCopy
// on ignore les commentaires Java (les mêmes qu'en C++)
#ignore(C++)
=> local sClassName;
// recherche du nom de la classe, utile pour la trace console
->[
#readIdentifier:"class"
#readIdentifier:sClassName
]
// parcours de toutes les méthodes sans type de retour, et
// injection du code de la trace, si pas déjà présente
[
->[
#readIdentifier:"void"
#readIdentifier:sMethod
// on prévient l'opérateur de saut que si l'on échoue à cette tentative,
// il faudra tenter à nouveau à partir du caractère suivant l'identifiant
// plutôt que d'avancer d'un seul caractère
#nextStep
'(' ->')'
'{'
[
// si l'on a déjà traité cette méthode lors d'une transformation
// précédente, inutile d'y revenir
"System.out.println(\"IN " sClassName "::"
|
=> {
// dès le début de la méthode, on place un message d'entrée,
// et le reste est mis dans un 'try ... finally' de manière
// à afficher le message de sortie dans tous les cas
@
System.out.println("IN @sClassName@::@sMethod@");
try {@
}
// on saute à la fin de la méthode, devant l'accolade fermante du corps
read_brackets
=> {
// à la fin de la méthode, on injecte la trace de sortie
@
} finally {
System.out.println("OUT @sClassName@::@sMethod@");
}
@
}
]
]
]*
->#empty
;
// lire des accolades, éventuellement imbriquées
read_brackets ::=
[
// accolade imbriquée
'{' #continue read_bracket '}'
|
// il ne faut pas se laisser abuser par les accolades contenues
// dans une constante chaîne de caractères ou caractère seul :
// on les ignore pour éviter toute ambiguïté
[#readCChar | #readCString]
|
// on s'arrête lorsqu'on a atteint la fin du fichier source
// ou que l'on est tombé sur une accolade fermante...
// sinon on avance d'un caractère
~['}' | #empty]
]*
;
| #nextStep |
| On a découvert en passant une nouvelle directive BNF : #nextStep. Placée dans un opérateur
de saut, elle signifie qu'en cas d'échec de cette tentative, il ne faudra pas se déplacer d'un caractère et retenter
de là, mais recommencer à partir de la position dans le fichier de lecture notée lors de la rencontre du #nextStep.
Exemple :
Les deux règles cherchent un identifiant suivi d'une parenthèse ouverte, mais nous allons voir que la plus performante
est la seconde.
Supposons que ces deux règles appartiennent à une grammaire appliquée au fichier suivant :
++++ orties.demange = gratte() ++++
Les deux règles se comportent de la même manière pour consommer les caractères "++++ ". En revanche, elles
diffèrent sur la façon de passer la portion "orties." :
|
$TMP/Developpez.com/org/tutorial/examples/voiture.java
package org.tutorial.examples;
public class voiture extends Jouet {
public String alimentation() { return "piles"; }
public int piles() { return "4"; }
public String typeDePile() { return "LR6"; }
public void jouer() {
System.out.println("IN voiture::jouer");
try {
//##protect##"corps de la méthode 'jouer()'"
//##protect##"corps de la méthode 'jouer()'"
} finally {
System.out.println("OUT voiture::jouer");
}
}
}
Nous n'avons pas étudié ici une approche rationnelle pour automatiser les développements, partant des spécifications pour aboutir au
produit fini, mais plutôt introduit plusieurs facettes que l'on rencontre fréquemment dans un processus d'automatisation,
et la manière concrète avec laquelle on les exprime en CodeWorker. Il ne faut pas non plus voir dans cet article
une tentative de recensement formel des différentes façons d'automatiser le processus, mais bien une initiation par
la pratique.
On considère que chaque projet a ses propres spécificités, des contraintes extérieures à intégrer, un passif à traîner... Ceci
explique pourquoi nous ne nous sommes pas aventurés à proposer une démarche d'automatisation du processus de développement
qui soit universelle. nous préférons montrer par la pratique comment intégrer au mieux les contraintes imposées, et
accélérer malgré tout le processus de développement.
Au sortir de votre lecture, mon objectif serait atteint si cet article vous a montré le potentiel qui se cache derrière
la programmation générative, et vous a suggéré les solutions concrètes que vous pourriez mettre en place pour automatiser
certaines tâches au sein de vos projets de développement.
C'est dans le souci de vous apporter tous les éléments pratiques, que cet article se structure autour d'un guide du développeur
sur CodeWorker. Cet outil offre bien d'autres possibilités que nous n'avons pas abordé dans ce document, et
qui feront sans doute l'objet d'autres articles : ajouter des plugins à CodeWorker, l'embarquer comme langage de
script pour le parsing et la génération dans une application C++, retranscrire les scripts CodeWorker en
C++ et disposer d'un exécutable, faire de la Programmation Orientée-Aspect...
public class voiture extends Jouet {
public String alimentation() { return "piles"; }
public int piles() { return "4"; }
public String typeDePile() { return "LR6"; }
public void jouer() {
System.out.println("IN voiture::jouer");
try {
//##protect##"corps de la méthode 'jouer()'"
//##protect##"corps de la méthode 'jouer()'"
} finally {
System.out.println("OUT voiture::jouer");
}
}
}